在 Java 中解析 XML,主流常用的方法有四种:DOM、SAX、JDOM 和 DOM4J 。
其中,DOM 和 SAX 是两种不同的 XML 解析方式,JDK 已经提供了支持 DOM 方式和 SAX 方式的具体实现,因此可以不引入第三方 jar 包来使用这两种解析方式。
JAXP(Java API for XML Processing):JAXP 类库是 JDK 的一部分,它由以下几个包及其子包组成:
org.w3c.domorg.xml.saxjavax.xml
JDOM 和 DOM4J 是在这两种方式的基础上发展出的 XML 解析类库,看名字就知道这是只能在 Java 平台使用的类库。
需要注意的是:DOM 和 SAX 是两种解析 XML 的方式,这两种方式与编程语言无关,针对不同的编程语言都有具体的实现。而在 Java 中,针对这两种方式及衍生方式实现的类库有很多,有 JDK 自带的 DOM 解析类库、SAX 解析类库和 StAX 解析类库(和 SAX 类似但有区别),还有第三方的 DOM4J 解析类库和 JDOM 解析类库等。
DOM(Document Object Model) DOM 是与平台和编程语言无关的 W3C 的标准,基于 DOM 文档树,在使用时需要加载和构建整个文档形成一棵 DOM 树放在内存当中。
优点
允许应用程序对数据和结构做出更改,即 CRUD 操作。
缺点
需要加载整个 XML 文档来构造层次结构,文档越大,消耗资源越多。
在使用 DOM 的方式解析 XML 之前,需要了解 DOM 中的节点类型:
W3C XML DOM 节点类型:http://www.w3school.com.cn/xmldom/dom_nodetype.asp
常用的节点:
节点类型
描述
NodeType
nodeName
nodeValue
Document
表示整个文档(DOM 树的根节点)
9
#document
null
Element
表示 element(元素)元素
1
element name
null
Attr
属性名称
2
属性名称
属性值
Text
表示元素或属性中的文本内容
3
#text
节点内容
Comment
表示注释
8
#comment
注释文本
DOM 解析过程及常用方法:
使用 JAXP 的 DOM 解析方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <root > <animate id ="0" > <name > 希德尼娅的骑士 </name > <published > 2014.04</published > </animate > <animate id ="1" > <name > 恶之华 </name > <published > 2013.04</published > </animate > <animate id ="2" > <name > 化物语 </name > <published > 2009.07</published > </animate > <animate id ="3" > <name > 穿越时空的少女 </name > <published > 2006.07</published > </animate > </root >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 package com.nekolr;import org.w3c.dom.*;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import java.util.Objects;public class DOMResolver { public static final String URI = System.getProperty("user.dir" ) + "/target/classes/nekolr.xml" ; public static void main (String[] args) throws Exception { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = dbf.newDocumentBuilder(); Document doc = db.parse(URI); Element root = doc.getDocumentElement(); Node comment = doc.getFirstChild(); NodeList nodeList = doc.getElementsByTagName("animate" ); for (int i = 0 , len = nodeList.getLength(); i < len; i++) { Node node = nodeList.item(i); if (node.hasAttributes()) printNodeAttrs(node); if (!node.hasChildNodes()) System.out.println("nodeName=" + node.getNodeName() + ", Text=" + node.getTextContent()); getChildNodes(node); } } public static void printNodeAttrs (Node node) { NamedNodeMap attrs = node.getAttributes(); if (!Objects.isNull(attrs)) { for (int i = 0 ; i < attrs.getLength(); i++) { Node attr = attrs.item(i); String name = attr.getNodeName(); String value = attr.getNodeValue(); System.out.println("nodeName=" + node.getNodeName() + ", attr=" + name + ", value=" + value); } } } public static void getChildNodes (Node node) { NodeList childNodes = node.getChildNodes(); for (int j = 0 ; j < childNodes.getLength(); j++) { Node child = childNodes.item(j); if (child.getNodeType() == Node.ELEMENT_NODE) { if (child.hasAttributes()) printNodeAttrs(child); if (!child.hasChildNodes()) System.out.println("nodeName=" + child.getNodeName() + ", Text=" + child.getTextContent()); else getChildNodes(child); } else if (child.getNodeType() == Node.TEXT_NODE && !"" .equals(child.getNodeValue().trim())) { System.out.println("nodeName=" + node.getNodeName() + ", Text=" + child.getTextContent()); } } } }
SAX(Simple API for XML) 与 DOM 的方式不同,SAX 方式不需要构建整个文档,基于流模型中的推(PUSH)模型,由事件驱动,从文档开始顺序扫描,每发现一个节点就引发一个事件,事件推给事件处理器,通过回调方法完成解析,因此读取文档的过程就是解析文档的过程。使用 SAX 需要两部分:SAX 解析器和事件处理器,其中事件处理器需要开发者提供,一般通过继承默认的事件处理器 DefaultHandler,重写需要的方法即可。
优点
不需要等待所有数据都被处理,分析就能立即开始。
缺点
需要应用程序自己负责节点的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂。
SAX 解析过程及使用:
使用 JAXP 的 SAX 解析方式(解析的 xml 同上):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package com.nekolr;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class SAXParserHandler extends DefaultHandler { boolean isName = false ; boolean isPublished = false ; @Override public void startDocument () throws SAXException { System.out.println("******文档解析开始******" ); } @Override public void endDocument () throws SAXException { System.out.println("******文档解析结束******" ); } @Override public void startElement (String uri, String localName, String qName, Attributes attributes) throws SAXException { if ("animate" .equals(qName)) { System.out.println("nodeName=" + qName + ", id=" + attributes.getValue("id" )); } else if ("name" .equals(qName)) { System.out.println("start element " + qName); isName = true ; } else if ("published" .equals(qName)) { System.out.println("start element " + qName); isPublished = true ; } } @Override public void endElement (String uri, String localName, String qName) throws SAXException { System.out.println("end element " + qName); } @Override public void characters (char [] ch, int start, int length) throws SAXException { if (isName) { System.out.println(new String (ch, start, length)); isName = false ; } else if (isPublished) { System.out.println(new String (ch, start, length)); isPublished = false ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.nekolr;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;public class SAXDemo { public static final String URI = System.getProperty("user.dir" ) + "/target/classes/nekolr.xml" ; public static void main (String[] args) throws Exception { SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser parser = factory.newSAXParser(); parser.parse(URI, new SAXParserHandler ()); } }
JDOM(Java-based Document Object Model) 为了减少 DOM 和 SAX 的编码量出现了 JDOM,JDOM 致力于成为 Java 特定文档模型,它遵循二八定律,底层仍然使用 DOM 和 SAX(使用 SAX 解析文档),并大量使用了 JDK 的 Collections。与 DOM 类似,JDOM 也将解析的 XML 以 DOM 树的方式放入内存中。
优点
不使用接口,使用具体实现类,简化了 DOM 的 API。
缺点
由于与 DOM 类似的生成 DOM 树结构,使得 JDOM 在处理大型 XML 文档时性能较差。
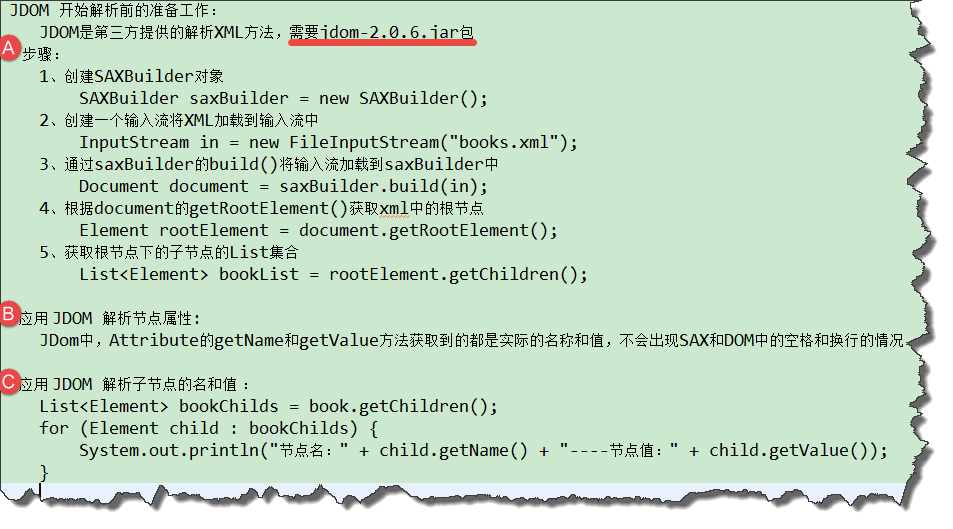
JDOM 的使用:
使用 JDOM 解析之前的 XML 文档,因为是第三方类库,需要引入 jar 包:
1 2 3 4 5 6 7 8 9 10 <dependencies > <dependency > <groupId > org.jdom</groupId > <artifactId > jdom2</artifactId > <version > 2.0.6</version > </dependency > </dependencies >
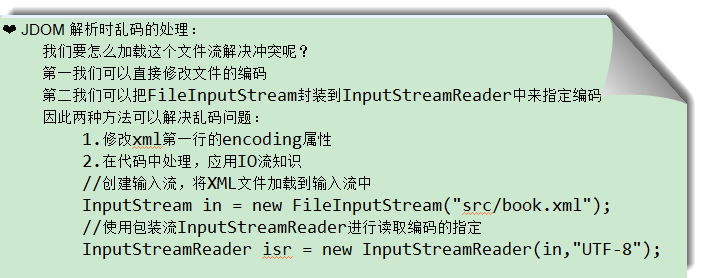
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.nekolr;import org.jdom2.Attribute;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.input.SAXBuilder;import java.io.FileInputStream;import java.io.InputStreamReader;import java.util.List;public class JDOMDemo { public static final String URI = System.getProperty("user.dir" ) + "/target/classes/nekolr.xml" ; public static void main (String[] args) throws Exception { SAXBuilder saxBuilder = new SAXBuilder (); InputStreamReader in = new InputStreamReader (new FileInputStream (URI), "utf-8" ); Document doc = saxBuilder.build(in); Element root = doc.getRootElement(); List<Element> animates = root.getChildren(); for (Element animate : animates) { Attribute id = animate.getAttribute("id" ); System.out.println("nodeName=" + animate.getName() + " ,id=" + id.getValue()); List<Element> children = animate.getChildren(); for (Element child : children) { System.out.println("nodeName=" + child.getName() + ", Text=" + child.getText()); } } } }
DOM4J(Document Object Model for Java) DOM4J 大量使用 JDK 的 Collections,同时也提供了一些高性能的替代方法。支持 DOM、SAX 和 JAXP,支持 XPath。使用接口和抽象类,牺牲了部分 API 的简易性来获得更高的灵活性,同时在解析大型文档时内存占用较低。具有性能优异、功能强大、灵活性高、易用性强等优点,被现在很多开源项目使用。
使用 DOM4J 解析之前的 XML 文档,引入第三方 jar:
1 2 3 4 5 6 7 8 9 10 <dependencies > <dependency > <groupId > dom4j</groupId > <artifactId > dom4j</artifactId > <version > 1.6.1</version > </dependency > </dependencies >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.nekolr;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;import java.util.Iterator;public class DOM4JDemo { public static final String URI = System.getProperty("user.dir" ) + "/target/classes/nekolr.xml" ; public static void main (String[] args) throws Exception { SAXReader saxReader = new SAXReader (); Document doc = saxReader.read(URI); Element root = doc.getRootElement(); for (Iterator iterator = root.elementIterator(); iterator.hasNext(); ) { Element animate = (Element) iterator.next(); Attribute id = animate.attribute("id" ); System.out.println("nodeName=" + animate.getName() + " ,id=" + id.getValue()); for (Iterator iter = animate.elementIterator(); iter.hasNext(); ) { Element ele = (Element) iter.next(); System.out.println("nodeName=" + ele.getName() + ", Text=" + ele.getText()); } } } }
参考
本文部分图片引用自:http://www.cnblogs.com/Qian123/p/5231303.html