Mark Word 用于存储对象自身的运行时数据,如 HashCode 、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳(epoch)等。这部分数据的长度在 32 位和 64 位虚拟机(未开启压缩指针)中分别为 32bit 和 64bit。由于 Mark Word 的信息与对象自身定义的数据无关,考虑到虚拟机的空间效率,它被设计为非固定的数据结构,它会根据对象的状态复用存储空间。
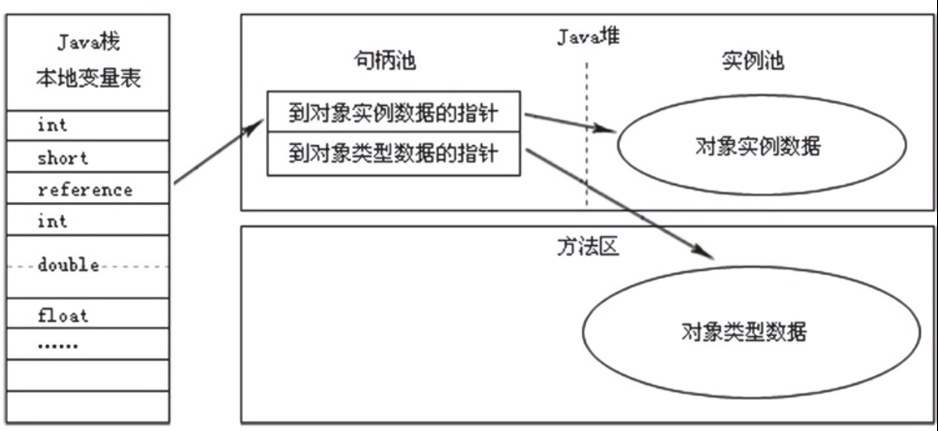
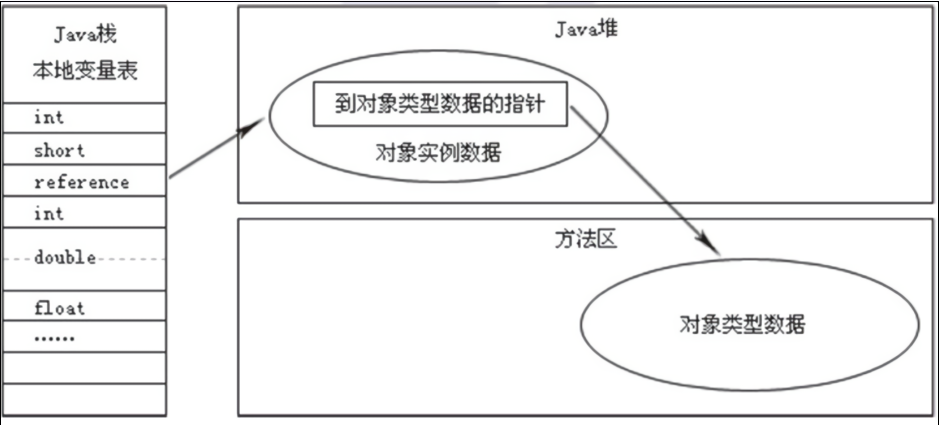
Klass Word,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定该对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象头存储类型指针(Java 程序通过栈上的 reference 数据来操作堆上的具体对象,由于虚拟机规范中只规定了一个指向对象的引用,并没有定义这个引用应该使用何种方式去定位、访问堆中的对象的具体位置,所以对象访问方式取决于虚拟机的实现,主流的访问方式有使用句柄和直接指针两种,而使用句柄的方式不需要在对象头中存储类型指针)。
|----------------------------------------------------------------------------------------|--------------------| | Object Header (64 bits) | State | |-------------------------------------------------------|--------------------------------|--------------------| | Mark Word (32 bits) | Klass Word (32 bits) | | |-------------------------------------------------------|--------------------------------|--------------------| | identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Normal | |-------------------------------------------------------|--------------------------------|--------------------| | thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Biased | |-------------------------------------------------------|--------------------------------|--------------------| | ptr_to_lock_record:30 | lock:2 | OOP to metadata object | Lightweight Locked | |-------------------------------------------------------|--------------------------------|--------------------| | ptr_to_heavyweight_monitor:30 | lock:2 | OOP to metadata object | Heavyweight Locked | |-------------------------------------------------------|--------------------------------|--------------------| | | lock:2 | OOP to metadata object | Marked for GC | |-------------------------------------------------------|--------------------------------|--------------------|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 64 位虚拟机对象头(未启用指针压缩)
|------------------------------------------------------------------------------------------------------------|--------------------| | Object Header (128 bits) | State | |------------------------------------------------------------------------------|-----------------------------|--------------------| | Mark Word (64 bits) | Klass Word (64 bits) | | |------------------------------------------------------------------------------|-----------------------------|--------------------| | unused:25 | identity_hashcode:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Normal | |------------------------------------------------------------------------------|-----------------------------|--------------------| | thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Biased | |------------------------------------------------------------------------------|-----------------------------|--------------------| | ptr_to_lock_record:62 | lock:2 | OOP to metadata object | Lightweight Locked | |------------------------------------------------------------------------------|-----------------------------|--------------------| | ptr_to_heavyweight_monitor:62 | lock:2 | OOP to metadata object | Heavyweight Locked | |------------------------------------------------------------------------------|-----------------------------|--------------------| | | lock:2 | OOP to metadata object | Marked for GC | |------------------------------------------------------------------------------|-----------------------------|--------------------|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 64 位虚拟机对象头(启用指针压缩)
|--------------------------------------------------------------------------------------------------------------|--------------------| | Object Header (96 bits) | State | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | Mark Word (64 bits) | Klass Word (32 bits) | | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | unused:25 | identity_hashcode:31 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Normal | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | thread:54 | epoch:2 | cms_free:1 | age:4 | biased_lock:1 | lock:2 | OOP to metadata object | Biased | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | ptr_to_lock_record | lock:2 | OOP to metadata object | Lightweight Locked | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | ptr_to_heavyweight_monitor | lock:2 | OOP to metadata object | Heavyweight Locked | |--------------------------------------------------------------------------------|-----------------------------|--------------------| | | lock:2 | OOP to metadata object | Marked for GC | |--------------------------------------------------------------------------------|-----------------------------|--------------------|
当对象在无锁状态时,HashCode 会懒初始化,它只会在调用 System#identityHashCode(object) 之后被初始化。而在其他状态时,HashCode 将不在 Mark Word 中存储,它会被存储到 monitor 中。GC 分代年龄长度只有四位,因此最大年龄为 15,超过该年龄对象会被转移到老年代。当对象在轻量级锁状态时,ptr_to_lock_record 指向锁记录,该记录在当前线程的栈帧中存储,锁记录中存储了锁对象的 Mark Word 的拷贝。线程获取轻量级锁的过程为使用 CAS 将对象的 Mark Word 更新为指向锁记录的指针,更新成功则表示获取到了轻量级锁。当对象升级为重量级锁时,ptr_to_heavyweight_monitor 指向 monitor。