Redis 入门
Redis 是一个开源高性能的 key-value 数据库软件,主要有以下特性:
- 可以将数据存储在内存,同时支持持久化到磁盘。
- 支持的数据类型丰富,包括 String、List、Set、Stored Set、Hash 等。
- 支持 master-slave 模式的数据备份和同步。
- 所有的单个操作都是原子性的,同时多个操作也支持事务,通过 MULTI 和 EXEC 包装。
Redis 分为服务端和客户端,一个服务端可以与多个客户端建立连接,每个客户端向服务端发送命令请求,服务端接收请求处理后返回信息给客户端。除了自带的 redis-cli,还可以使用其他语言提供的客户端来操作。
配置
- 获取所有配置项
CONFIG GET * - 获取某个配置
CONFIG GET config_setting_name - 修改配置
CONFIG SET config_setting_name new_config_value
数据结构
简单动态字符串
Redis 底层使用的字符串是 Sds(Simple Dynamic String,简单动态字符串),使用 Sds 主要用于实现字符串对象(StringObject),并在内部替换 char* 类型。
用途
实现字符串对象
Redis 是一个 key-value 数据库,数据库的值可以是字符串,也可以是集合、列表等类型,但是数据库的键则总是字符串对象。Redis 中,一个字符串对象除了可以保存字符串值之外,还可以保存 long 类型的值。当字符串对象保存的是字符串时,它包含的才是 Sds 值;否则,它就是一个 long 类型的值。比如:
1 | :: 这里的键和值都是字符串对象,它们都包含一个 Sds 值 |
替换 char*
Redis 使用 Sds 替换 C 语言中的 char* 是因为在 Redis 内部,字符串的追加和长度计算很常见,甚至有专门的命令:APPEND 和 STRLEN,使用 C 语言提供的 char 类型数组并不能进行高效的长度计算和追加操作。
C 语言中的字符串不会记录自己的长度,当需要获取长度的时候,需要遍历整个字符数组,直到遇到空字符为止,时间复杂度为 O(N),而 sds 保存了自身的长度,在需要时直接获取,时间复杂度为 O(1)。
C 语言中在进行字符串的扩充和收缩时,都需要重新分配内存空间。
- 字符串拼接会导致字符串内存空间的扩充(字符数组的扩容),如果在拼接的过程中忘记申请内存空间,就会面临内存溢出的危险。
- 字符串切割会导致字符串内存空间的收缩(字符数组的分割),如果在字符串切割的时候没有对内存空间重新分配,那么多出来的空间就会发生内存泄露。
Redis 通过内存的预分配和惰性释放来优化内存分配的问题。
Sds 的数据结构
1 | typedef char *sds; |
sds 由两部分组成,typedef char *sds 表示 sds 是 char * 类型的别名,结构体 sdshdr 则包含 len、free 和 buf 三个属性。比如:
1 | struct sdshdr { |
优化追加操作
通过一个例子来说明追加时发生了什么。
首先执行 SET message Hello World,SET 命令会创建 sdshdr,但是 free 的值为 0。
1 | struct sdshdr { |
然后执行 APPEND message " Avalon",此时 free 变为 18。
1 | struct sdshdr { |
使用 APPEND 命令会根据追加后内容的长度来预先分配 len 长度的空间,如果后续又使用 APPEND 命令追加内容,而内容的长度不超过 free 的大小,则不用再分配空间。
sds.c/sdsMakeRoomFor 函数描述这种内存预分配优化策略,以下为伪代码:
1 | def sdsMakeRoomFor(sdshdr, required_len) { |
当前的 Redis 版本为 5.0 RC3,SDS_MAX_PREALLOC 的值还是 1024*1024,也就是 1MB。
APPEND 的这种预先分配策略的代价就是会有额外的内存占用,这些预分配的空间只有在字符串对应的键被删除或者 Redis 实例停止时才被回收。这种以空间换时间的方式,在现在内存成本相对较低的背景下是有价值的。当然,如果 APPEND 操作过多,同时字符串的体积较大时,可能就需要调整 Redis 的配置,使它定时释放一些字符串键的预分配内存。
惰性释放
当字符串进行切割缩短操作时,并不立即释放空间,而是将这部分空间通过 free 标识,这样在下次使用该字符串操作时可很有可能会避免再次分配内存。同时 Redis 还提供了专门的 API 来释放这部分空余的空间。
二进制安全
C 语言的字符串,除了末尾处,其他位置不能包含空字符,否则会被认为是字符串的结尾,从而导致读取数据时丢失后边的字符。这个限制导致了字符串不能存储图片、音视频等二进制数据。Redis 不是通过空字符来判断字符串是否结束的,它通过结构体中的 len 属性来判断,所以 Redis 可以存储文本和任意二进制数据。
双端链表
由于 C 语言本身不支持链表类型,所以大部分的 C 语言程序都会自己实现链表结构,Redis 实现的是双端链表。Redis 的 List 使用了两种数据结构:双端链表和压缩列表。因为双端链表占用内存比压缩列表多,所以当创建新的列表键时,列表会优先考虑使用压缩列表作为底层实现,只有在有需要的时候才转换成双端链表。
用途
除了实现 List 外,双端链表还被很多 Redis 内部模块使用,比如:
- 事务模块使用双端链表依序保存输入的命令
- 服务端使用双端链表保存建立连接的多个客户端
- 订阅/发布模块使用双端链表保存订阅的客户端
- 事件模块使用双端链表保存时间事件
双端链表的数据结构
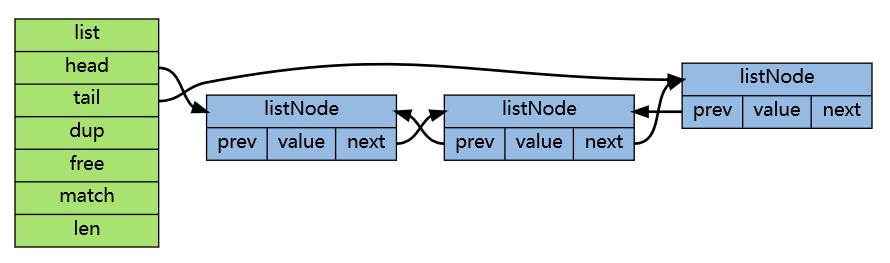
源代码在 addlist.h 中。
1 | typedef struct listNode { |
1 | typedef struct list { |
根据这两个结构的定义,可以了解到双端列表的一些特性:
- listNode 的 value 属性类型为 void *,也就是说双向链表对于节点保存的值的类型没有限制。
- 由于保存了 head 和 tail 两个指针,所以对链表的头部和尾部插入元素的复杂度都为 O(1),这也是命令
LPUSH、RPOP和RPOPLPUSH高效的原因。 - 双向链表保存有节点数量的 len 属性,所以计算长度的复杂度也为 O(1),即
LLEN命令的时间复杂度为 O(1)。
Redis 还为双端链表实现了一个迭代器,支持从前往后和从后往前两个方向进行迭代。
1 | typedef struct listIter { |
字典
字典(dictionary)又名映射(map),由一个个键值对组成。它主要有两个用途:
- 实现数据库键空间(key space)
- 用作 Hash 类型的底层实现之一
用途
实现数据库键空间
Redis 是 key-value 数据库,在 Redis 实例内部维护着一个数据库数组,每个元素都是一个数据库,在实例初始化时,默认会创建 16 个数据库,每个数据库都有一个对应的字典,这个字典就是键空间(key space)。当用户添加一个键值对到其中某个数据库时,不论键值对的值是什么类型(List、Set、String、Hash 等等),都会将该键值对添加到该数据库对应的键空间中。
1 | :: 选择 0 号数据库 |
用作 Hash 类型的底层实现之一
Redis 中的 Hash 类型使用字典或压缩列表来实现。因为压缩列表更节省内存,所以在创建新的 Hash 键时,默认使用压缩列表作为底层实现,只有在需要时才转换为字典。
字典的数据结构
字典的定义在 dict.h
1 | typedef struct dict { |
dict 使用了两个指针,分别指向两个哈希表。其中,0 号哈希表是字典主要使用的哈希表,1 号哈希表则在对 0 号哈希表进行 rehash 时才使用。
1 | typedef struct dictht { |
table 是一个数组,数组的元素是指向 dictEntry 结构的指针。
1 | typedef struct dictEntry { |
总体结构如下图:
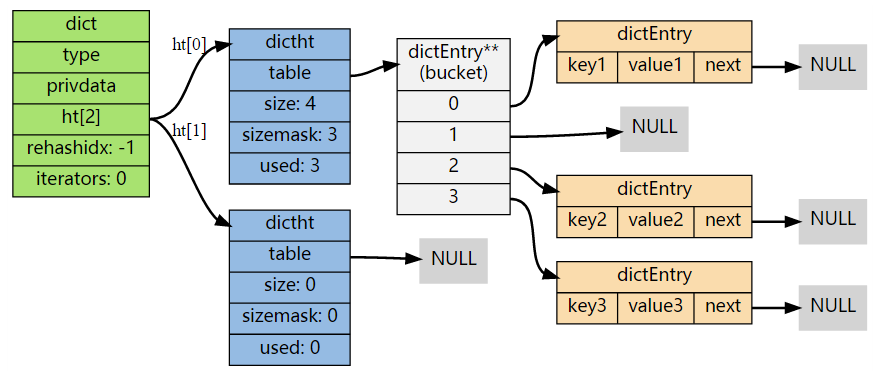
创建字典
dictCreate 函数创建并返回一个新的字典:
1 | dict *d = dictCreate(&hash_type, NULL); |
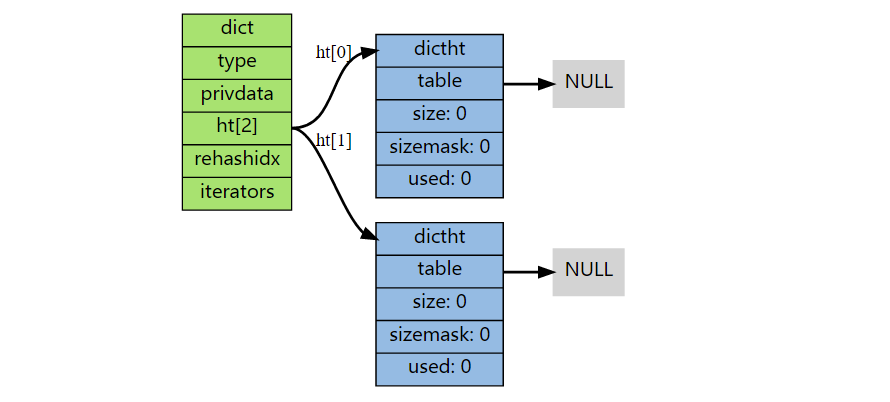
新创建的字典中,两个哈希表都没有分配任何空间,只有在以下情况才会分配:
- ht[0]->table 的空间在第一次向字典中添加键值对时分配
- ht[1]->table 的空间在 rehash 开始时分配
添加键值对
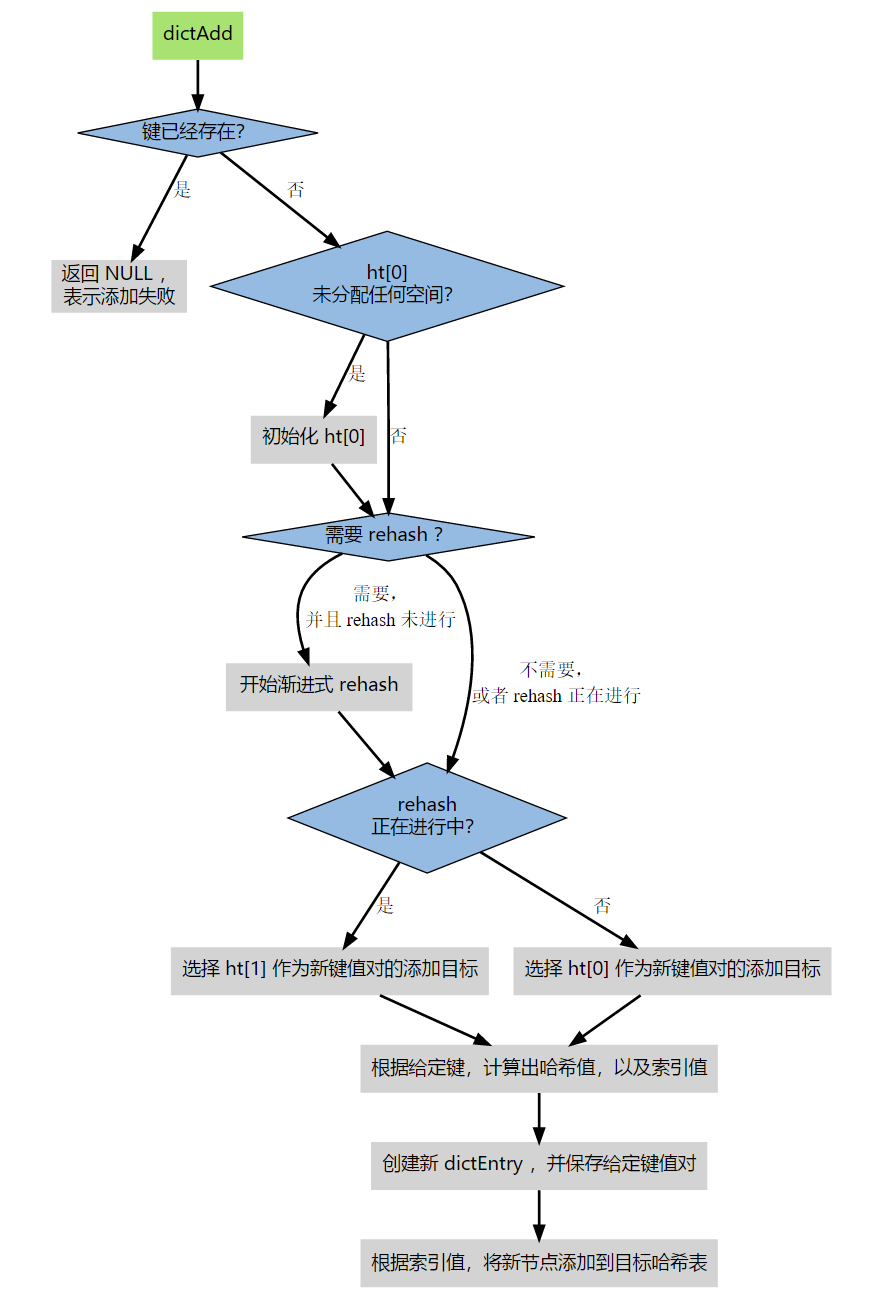
其中,有三种特殊的情况需要处理:
- 字典没有初始化
- 添加键值对时发生哈希冲突
- 添加键值对时触发了 rehash 操作
初始化字典
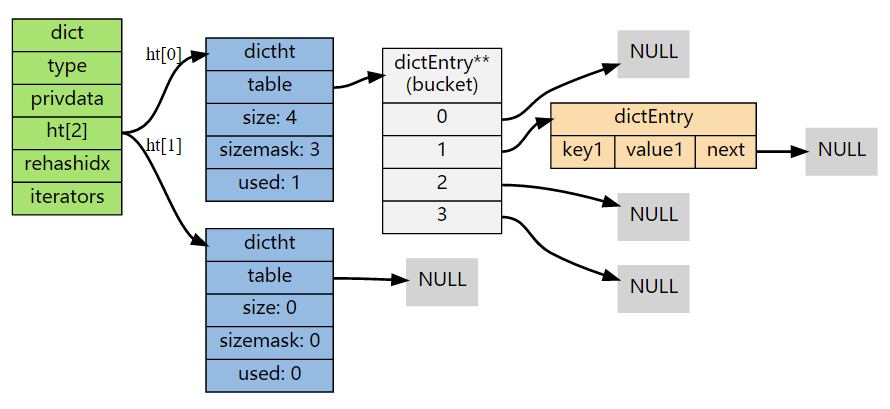
添加键值对,结果发现字典还没有初始化,则会执行初始化操作。根据 dict.h/DICT_HT_INITIAL_SIZE 里指定的大小为 ht[0]->table 分配空间,当前版本 5.0-rc3 中该值为 4。
字典未初始化时:
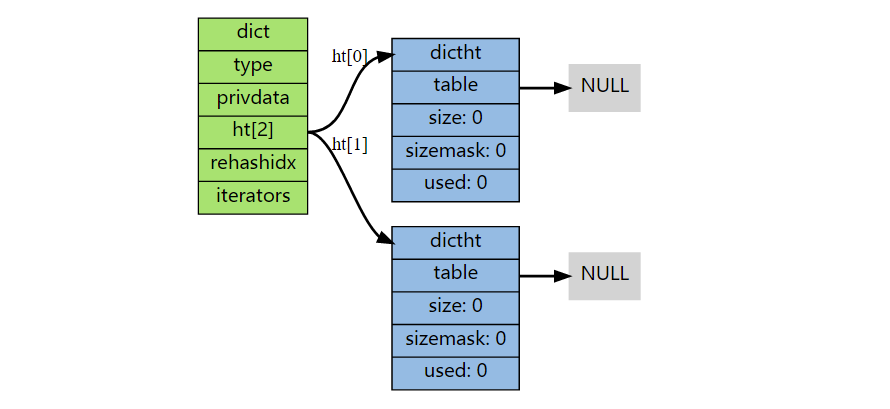
字典初始化,并添加了一个键值对后:
哈希冲突的解决
字典解决哈希冲突采用的方法为链地址法,即将哈希值相同的节点放在桶结构上,形成一个链表。
没有哈希冲突时:
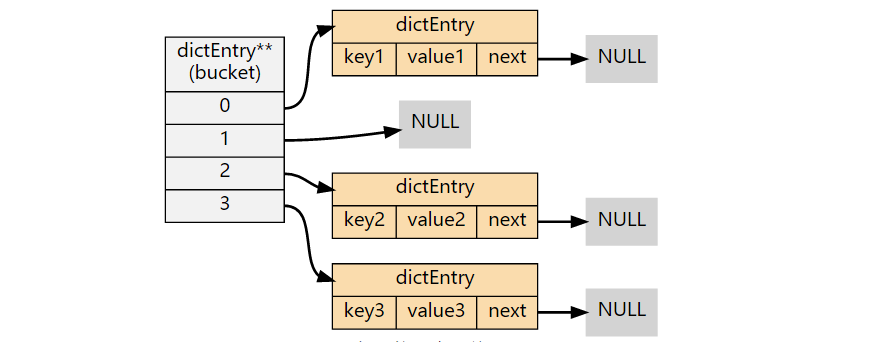
哈希冲突时:
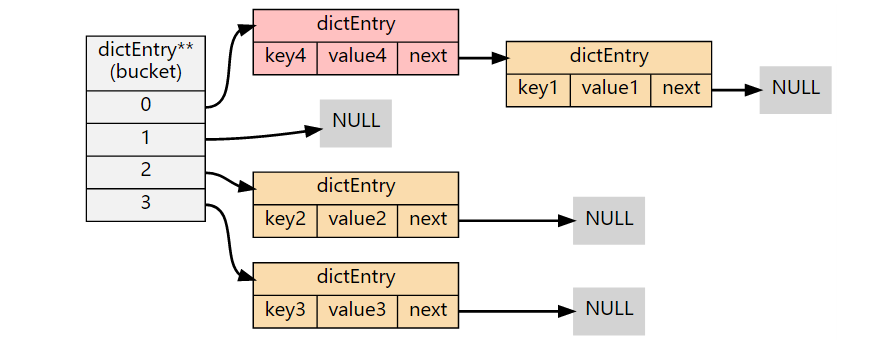
触发 rehash 操作
使用链地址法处理冲突时,如果冲突比较严重,哈希表的查找性能会严重下降。最坏的情况下会退化成线性查找,即所有的节点都在一个桶结构上,时间复杂度为 O(N)。哈希表的性能可以通过哈希表的大小(数组大小,size)与节点数量(used)之间的比率来衡量。
当哈希表的大小和节点的数量为 1:1 时,性能和空间利用率最好;如果哈希表中节点数量比哈希表的大小大很多时,哈希表很可能是退化成了多个链表,这时查找性能就会下降,此时就需要对哈希表进行扩容。
dictAdd 函数的作用是添加新的键值对到字典中。该方法在添加键值对之前都会对哈希表 ht[0] 进行检查,判断 ratio = used / size 的值:
1 | if (d->ht[0].used >= d->ht[0].size && |
- 当 ratio >= 1,且变量 dict_can_resize 为 true 时,执行 rehash
- 当 ratio > dict_force_resize_ratio(当前版本 Redis 5.0-rc3 值为 5)时,即使 dict_can_resize 为 false(有持久化任务在进行),字典也会强制执行 rehash。
当 Redis 使用子进程对数据库执行后台持久化任务(比如 BGSAVE 或 BGREWRITEAOF)时,为了最大化利用系统的 copy on write 机制,程序会暂时将 dict_can_resize 设置为 false,避免执行自然 rehash,从而减少程序对内存的触碰(touch)。当持久化任务完成后,dict_can_resize 会被重新设置为 true。
rehash 执行过程
字典的 rehash 过程主要包括:
- 创建一个比 ht[0]->table 更大的 ht[1]->table
- 将 ht[0]->table 中所有的键值对迁移到 ht[1]->table
- 清空 ht[0] 的数据,用 ht[1] 替换 ht[0] 后再将 ht[1] 置为空
开始 rehash
- 在需要扩容,执行 dictExpand 方法时,rehashidx 就被设置成了 0,这标志着 rehash 的开始。
- 为 ht[1]->table 分配空间,大小至少是 ht[0]->table 的 2倍。
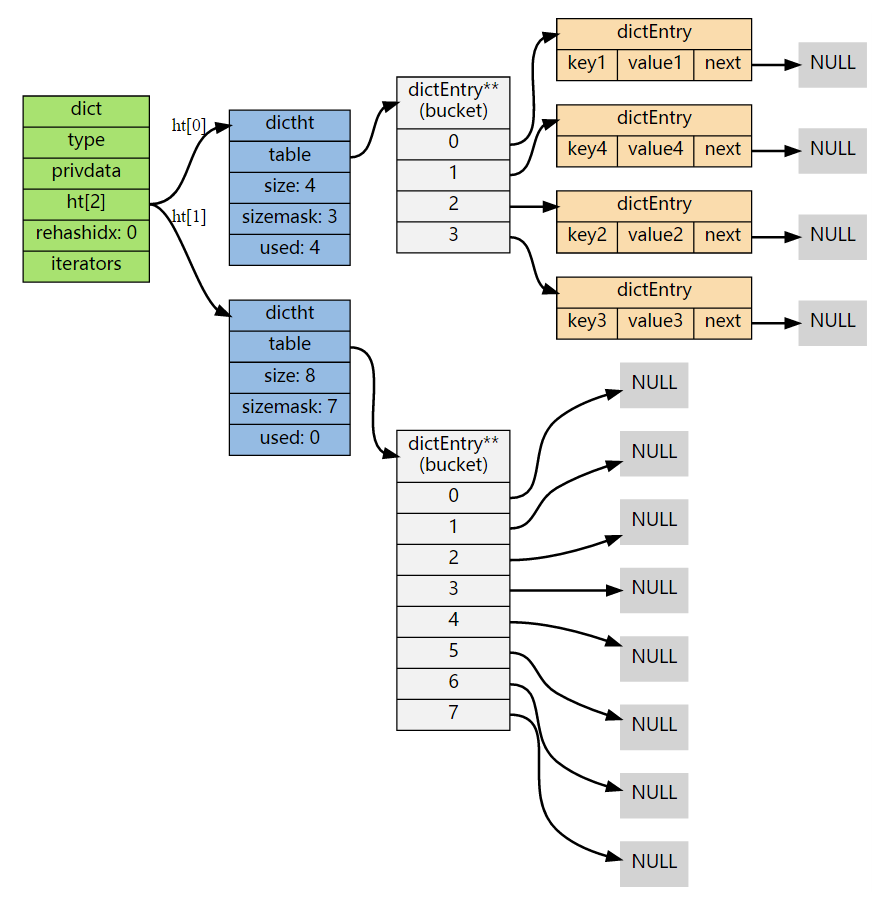
rehash 进行中
在这个阶段,ht[0]->table 上的节点并不会一次性全部迁移,而是逐渐迁移到 ht[1]->table 上,字典的 rehashidx 会记录 rehash 进行到了 ht[0] 的哪个位置。以下是 rehashidx 值为 2 时,字典的样子:
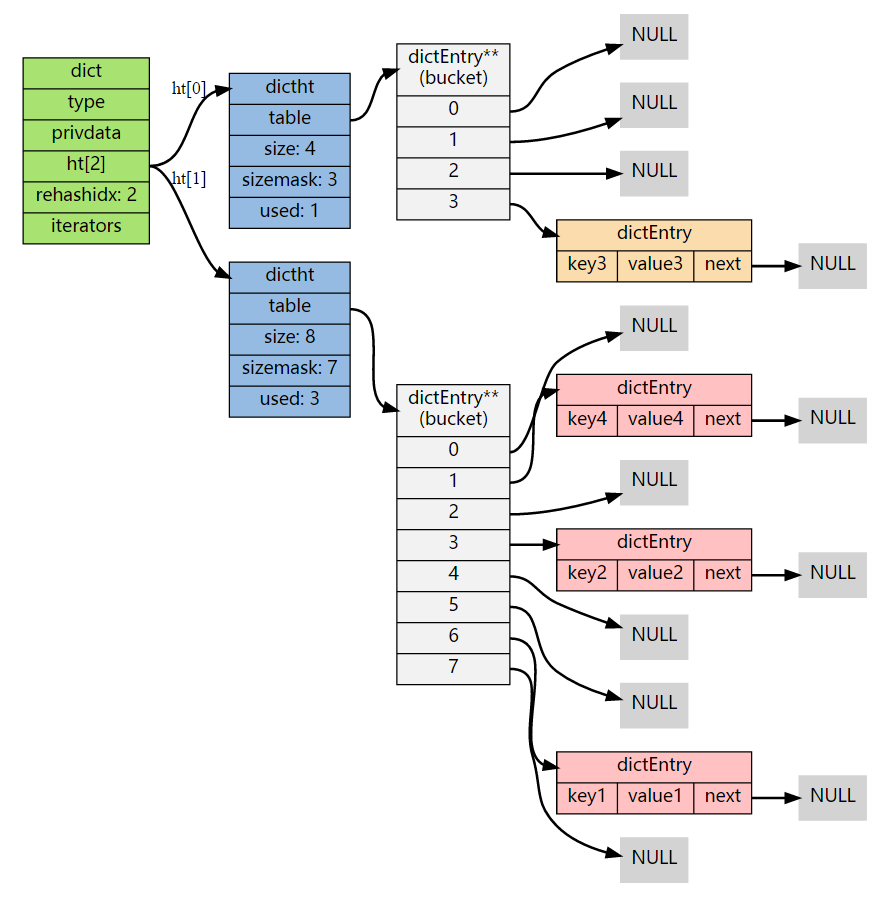
节点迁移完毕
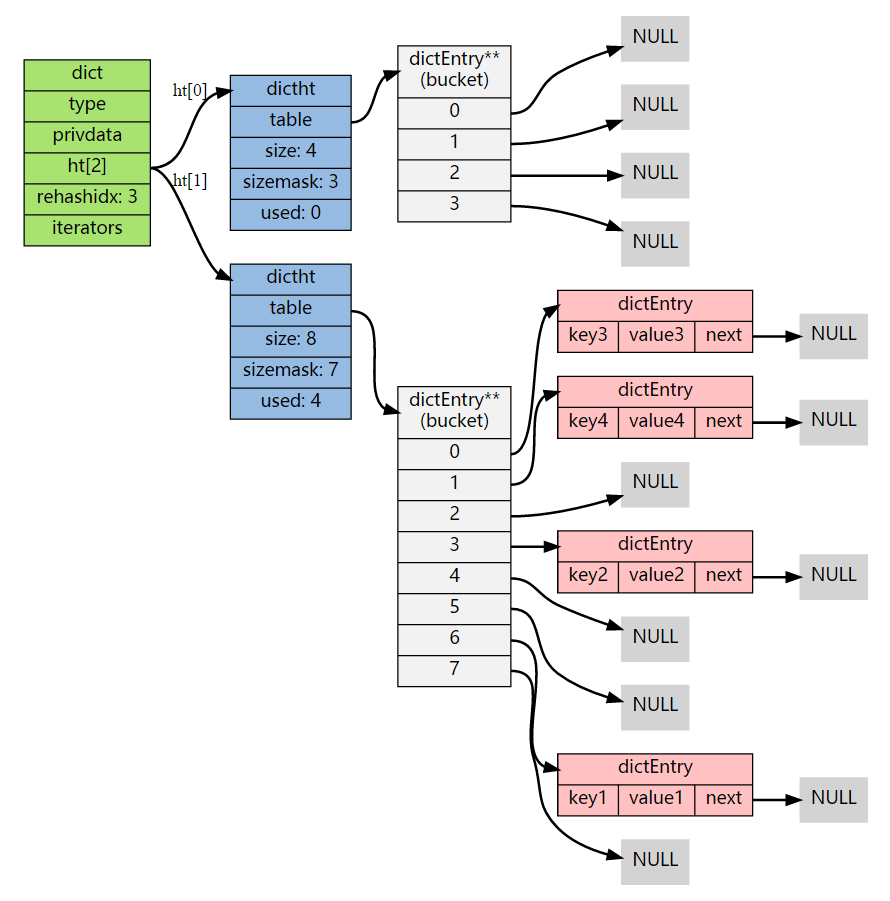
rehash 完毕
节点迁移完毕后,还需要执行以下步骤:
- 释放 ht[0] 的空间
- 将 ht[0] 指向 ht[1]
- 将 ht[1] 指向一个新的空哈希表
- 将字典的 rehashidx 重新设置为 -1,表示 rehash 已经结束
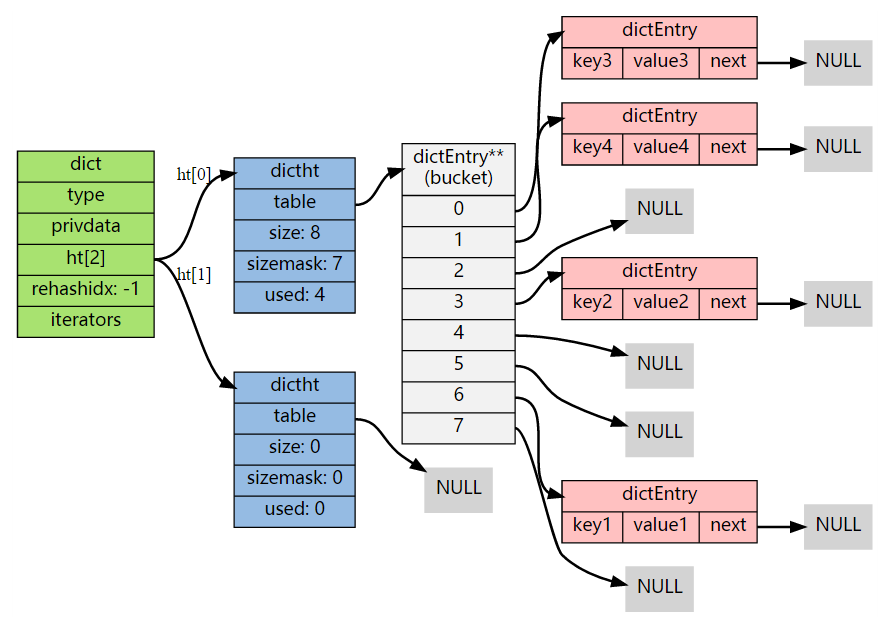
渐进式 rehash
rehash 并不是在启动后就立马执行直到完成,而是分为多次、渐进式地完成。
如果在一个有很多键值对的字典中,用户频繁添加新的键值对,可能会多次触发 rehash,如果每次都需要将全部节点迁移完毕才能继续,这对用户来说是很不友好的。并且,由于 Redis 使用的是单线程,如果必须要等待 rehash 的完成才能执行其他操作,这期间 Redis 会一直阻塞,这也是不能接受的,因此 Redis 将 rehash 的过程分散到多个步骤中进行来避免集中式的计算。
渐进式 rehash 主要由 _dictRehashStep 和 dictRehashMilliseconds 两个函数来处理。
- _dictRehashStep 用于对数据库键空间以及哈希键的字典进行被动 rehash。
- dictRehashMilliseconds 则由 Redis 服务端常规任务程序执行,用于对数据库键空间进行主动 rehash。
_dictRehashStep
每次执行 _dictRehashStep,ht[0]->table 哈希表的第一个不为空的索引上的所有节点就会全部迁移到 ht[1]->table 上。
在 rehash 开始进行之后(d->rehashidx 不为 -1),每次执行一次添加、查找、删除操作,_dictRehashStep 都会被执行一次。
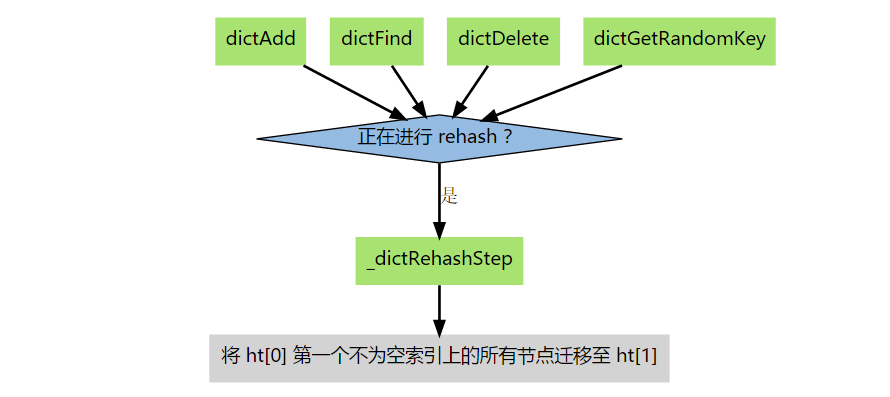
因为字典会让哈希表的大小和节点数量的比率维持在一个较小的范围内,所以每个索引上的节点数量不会很多,这样每次在执行添加、查找和删除操作的同时,对单个索引上的节点进行迁移就几乎不会对响应时间造成影响。
dictRehashMilliseconds
该方法可以在指定的毫秒时间内,对字典进行 rehash。当 Redis 服务端常规任务执行时会执行该方法,在规定的时间内,尽可能地对数据库中需要 rehash 的键空间进行 rehash。
其他措施
在哈希表进行 rehash 时,字典还会采取一些其他措施确保 rehash 顺利进行。
- 因为在 rehash 时,字典会同时使用两个哈希表,所以在这期间的所有查找、删除等操作,除了在 ht[0] 上进行,还会在 ht[1] 上进行。
- 在执行添加操作时,新的节点会被添加到 ht[1] 而不是 ht[0],这样保证 ht[0] 的节点数量在整个 rehash 过程中只会减少不会增加。
字典的收缩
如果哈希表的节点数量比哈希表的大小小很多的话,可以通过 rehash 对字典进行收缩。
收缩与扩展执行的 rehash 操作过程一样,区别是收缩时新分配的 ht[1]->table 空间要比 ht[0]->table 小。具体的收缩规则由 server.c/htNeedsResize 函数定义:
1 | /** |
DICT_HT_INITIAL_SIZE 的值默认为 4,HASHTABLE_MIN_FILL 的值默认是 10。也就是说,在字典的大小大于 4,并且字典的利用率小于 10% 时,就可以对字典进行收缩。
字典的收缩与字典的扩展不同的是,字典的扩展是自动触发的,而字典的收缩需要由程序手动执行。
- 当字典用于实现哈希键时,每次从字典中删除一个键值对都会执行一次 htNeedsResize 函数来决定是否要进行 rehash 操作来收缩字典。
- 当字典用于实现数据库键空间时,收缩的实际由 server.c/tryResizeHashTables 函数来决定。
字典的迭代
字典有自己的迭代器实现,在迭代时有如下几个规则:
- 迭代器首先迭代字典的第一个哈希表,如果 rehash 正在进行,就继续回第二个哈希表进行迭代。
- 当迭代哈希表时,找到第一个不为空的节点,然后迭代这个索引上的所有节点。
- 当一个索引迭代完了,会继续查找下一个不为空的节点,直到整个哈希表迭代完成。
字典的迭代器主要分为安全迭代器和不安全迭代器。安全迭代器在迭代的过程中,可以对字典进行修改;不安全迭代器在迭代的过程中,不能对字典进行修改。
跳跃表
为了满足自身的功能需要,Redis 基于 William Pugh 论文中描述的跳跃表进行了以下修改:
- 允许重复的 score 值,即多个不同的节点的 score 值可以相同。
- 进行比对操作时,不仅要检查 score 的值,还要检查数据域。当 score 值相同时,单靠 score 值无法判断一个元素的身份。
- 每个节点都带有一个高度为 1 层的后退指针,用于从表尾向表头方向迭代。当执行 ZREVRANGE 或 ZREVRANGEBYSCORE 这类逆序处理有序集的命令时,就会用到该属性。
用途
跳跃表的一个作用就是实现有序集合数据类型。
跳跃表的数据结构
1 | typedef struct zskiplist { |
1 | typedef struct zskiplistNode { |
内存映射数据结构
虽然 Redis 的内部数据结构很强大,但是创建一系列完整的数据结构本身也是挺耗费内存的,当一个对象包含的元素不多或元素本身的体积不大时,使用内部数据结构并不是最好的做法。为了解决这个问题,Redis 在条件允许的情况下,会使用内存映射数据结构来代替内部数据结构。内存映射数据结构是一系列经过特殊编码的字节序列,创建它们所消耗的内存通常比作用类似的内部结构要少得多,当然,创建它们所占用的 CPU 时间也会相对增多。
整数集合
整数集合(intset)用于有序的、无重复的保存多个整数值,根据元素的值,自动选择该用什么长度的整数类型来保存。假如在一个 intset 中最长的元素可以用 int16_t 类型存储,那么这个 intset 的所有元素都使用 int16_t 类型存储。如果有一个新元素加入,这个元素不能用 int16_t 类型存储,那么这个 intset 就会自动升级,先将集合中现有的元素从 int16_t 转换为 int32_t,然后再将新元素加入。根据需要,intset 可以一直升级到 int64_t。
用途
intset 是集合键的底层实现之一,如果一个集合只保存整数元素,并且元素的数量不多,则 Redis 默认会使用 intset 来保存元素。
整数集合的数据结构
1 | typedef struct intset { |
其中,encoding 的值可以是以下三个常量之一:
1 | /** |
contents 数组是保存元素的地方,数组中的元素有两个特点:
- 元素不重复
- 元素在数组中按从小到大排序
contents 数组的 int8_t 类型声明容易让人误解,其实 intset 不使用 int8_t 类型来直接保存元素,而是仅作为占位符使用,实际上 contents 数组的真正类型取决于 encoding 的值。当 encoding 的值为 INTSET_ENC_INT16 时,contents 就是一个 int16_t 类型的数组,encoding 为 INTSET_ENC_INT32时,contents 就是一个 int32_t 类型的数组。
创建整数集合
1 | /* Create an empty intset. */ |
添加元素
添加元素由 intset.c/intsetAdd 函数完成。
1 | /* Insert an integer in the intset */ |
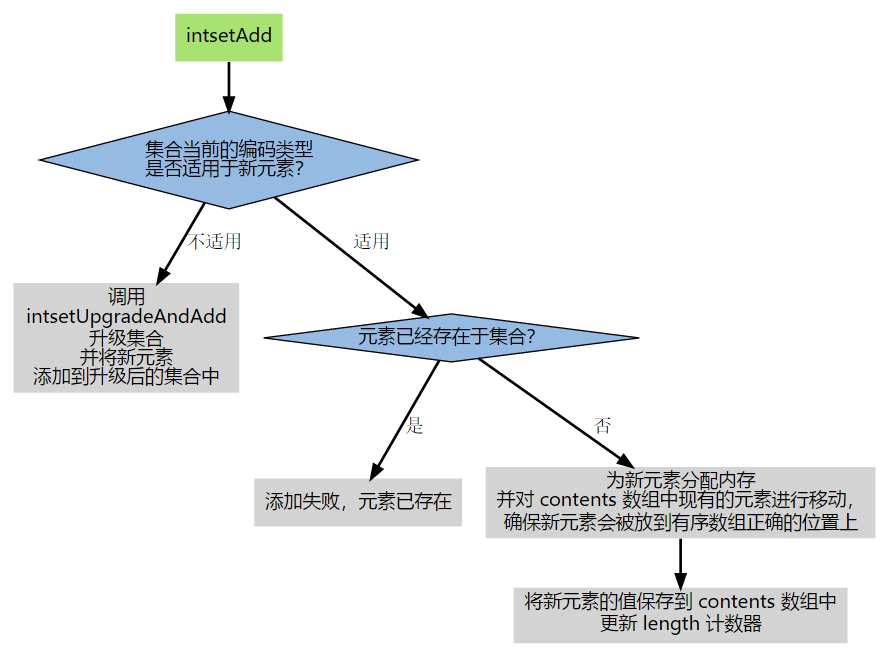
升级操作
添加元素时,如果发现现有的编码不能存储新元素,则通过 intsetUpgradeAndAdd 完成升级和添加元素的工作。
1 | /* Upgrades the intset to a larger encoding and inserts the given integer. */ |
1 | /* Set the value at pos, using the configured encoding. */ |
升级实例:
假设有一个 intset,里面有三个用 int16_t 方式保存的数值,分别是 1、2、3,结构如下:
1 | intset->encoding = INTSET_ENC_INT16; |
其中,intset->contents 在内存中的排列如下:
1 | bit 0 15 31 47 |
现在,我们将一个长度为 int32_t 的值 65535 加入到集合中,intset 需要执行以下步骤:
步骤一: 将 encoding 属性设置为 INTSET_ENC_INT32。
步骤二: 根据 encoding 属性的值,对 contents 数组进行内存重分配。
重分配完成之后,contents 在内存中的排列如下:
1 | bit 0 15 31 47 63 95 127 |
contents 数组现在一共有可容纳 4 个 int32_t 值的空间。
步骤三: 因为原来的 3 个 int16_t 值还挤在 contents 前面的 48 个位里,所以程序需要移动它们并转换类型,让它们适应集合的新编码方式。
- 首先移动 3
1 | bit 0 15 31 47 63 95 127 |
- 然后移动 2
1 | bit 0 15 31 47 63 95 127 |
- 再移动 1
1 | bit 0 15 31 47 63 95 127 |
- 最后添加元素
1 | bit 0 15 31 47 63 95 127 |
降级操作
intset 不支持降级操作。intset 定位为一种受限的中间表示,只能保存整数,而且元素的个数也有限制,因此没有必要进行很复杂的操作,而如果支持降级的话,代码的复杂度会增加很多。
压缩列表
压缩列表(ziplist)是由一系列特殊编码的内存块构成的列表,一个 ziplist 可以包含多个节点(entry),每个节点可以保存一个长度受限的字符数组(不以 \0 结尾)或者整数。
用途
为了节约内存,哈希键、列表键和有序集合键在初始化时底层使用的都是 ziplist。
压缩列表的构成
1 | |<---- ziplist header ---->|<----------- entries ------------->|<-end->| |
| 域 | 类型 | 说明 |
|---|---|---|
| zlbytes | uint32_t | 整个 ziplist 占用的内存字节数,对 ziplist 进行内存重分配,或者计算末端时使用。 |
| zltail | uint32_t | 到达 ziplist 表尾节点的偏移量。通过这个偏移量,可以在不遍历整个 ziplist 的前提下,弹出表尾节点。 |
| zllen | uint16_t | ziplist 中节点的数量。当这个值小于 UINT16_MAX(65535)时,这个值就是 ziplist 中节点的数量;当这个值等于 UINT16_MAX 时,节点的数量需要遍历整个 ziplist 才能计算得出。 |
| entry | ? | ziplist 所保存的节点,各个节点的长度根据内容而定。 |
| zlend | uint8_t | 255 的二进制值 1111 1111(UINT8_MAX),用于标记 ziplist 的末端。 |
节点的构成
一个 ziplist 可以包含多个节点,每个节点可以划分为以下几个部分。
1 | |<------------------- entry -------------------->| |
pre_entry_length
pre_entry_length 记录了前一个节点的长度,通过这个值进行指针运算可以跳转到上一个节点。
比如这样一个结构:
1 | |<---- previous entry --->|<--------------- current entry ---------------->| |
通过指向当前节点的指针 e,减去 pre_entry_length 的值(0101 是 5),得出的就是指向上一个节点的地址。
根据编码方式的不同,pre_entry_length 可能占用 1 个字节或 5 个字节。
- 如果前一个节点的长度小于 254 字节,则使用一个字节保存它的长度。
- 如果前一个节点的长度大于等于 254 字节,则将第一个字节的值设置为 254,然后用接下来的 4 个字节保存实际长度。
示例 1,前一个节点的长度为 128 字节
1 | |<------------------- entry -------------------->| |
示例 2,前一个节点的长度为 10086 字节,pre_entry_length 的前一个字节用 254 填充,之后的 4 个字节被设置为 10086。
1 | |<------------------------------ entry ---------------------------------->| |
encoding 和 length
encoding 决定了 content 保存的数据的类型,length 保存着 content 的长度。
其中,encoding 的长度为 2 个 bit,00、01 和 10 表示 content 保存着字符数组,11 表示 content 保存着整数。
下面列出以 00、01 和 10 开头的字符数组的编码方式:
| 最大编码 | 编码长度 | content 部分保存的值 |
|---|---|---|
| 00111111 | 1 byte | 长度最大为 2^6 - 1 字节的字符数组 |
| 01111111 11111111 | 2 byte | 长度最大为 2^14 - 1 字节的字符数组 |
| 10111111 11111111 11111111 11111111 11111111 | 5 byte | 长度最大为 2^32 - 1 字节的字符数组 |
下面列出以 11 开头的整数的编码方式:
| 编码 | 类型长度 | content 部分保存的值 |
|---|---|---|
| 11000000 | 2 byte | int16_t 类型的整数 |
| 11010000 | 4 byte | int32_t 类型的整数 |
| 11100000 | 8 byte | int64_t 类型的整数 |
| 11110000 | 3 byte | 24 bit 有符号整数 |
| 11111110 | 1 byte | 8 bit 有符号整数 |
| 1111xxxx | 4 bit | 4 bit 无符号整数,介于 0 到 12 之间(0000、1110 和 1111 已被占用,剩下 13 个值) |
content
content 保存着节点的内容,类型和长度由 encoding 和 length 决定。
例子:
1 | |<---------------------- entry ----------------------->| |
1 | |<---------------------- entry ----------------------->| |
创建压缩列表
函数 ziplistNew 用于创建一个新的空白 ziplist,这个空白的 ziplist 可以用下图表示:
1 | |<---- ziplist header ---->|<-- end -->| |
空白的 ziplist 表头、表尾和末端处于同一地址。
添加节点
添加节点到末端
将新节点添加到 ziplist 的末端需要以下几步:
- 记录到达 ziplist 末端的偏移量。
- 根据新节点的值计算编码这个值需要的空间大小,以及编码它的前一个节点的长度需要的空间大小,然后对 ziplist 重新分配内存。
- 设置新节点的各个属性。
- 更新 ziplist 的各个属性。
比如有这样一个压缩列表:
1 | |<---- ziplist header ---->|<--- entries -->|<-- end -->| |
假如要添加一个节点的值是一个字符数组 hello world,那么保存这个节点共需要 13 个字节的空间(1 个字节用来存 encodin 和 length,1 个字节用来存 前一个节点的长度为 5,11 个字节用来存字符数组)。
1 | |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->| |
然后更新节点的属性值。
1 | |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->| |
最后更新 ziplist 的各个属性。
1 | |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->| |
添加节点到某个节点前面
比起将新节点添加到 ziplist 的末端,将一个新节点添加到某个节点的前面要复杂的多,因为这种操作除了将新节点添加到 ziplist 以外,还可能引起后续一系列的变更。
比如,假设我们要将一个新节点 new 添加到节点 prev 和 next 之间。
1 | add new entry here |
首先为新节点扩大 ziplist 的空间。
1 | +----------+----------+----------+----------+----------+----------+ |
然后设置 new 的各个属性值。
1 | set value, |
设置完之后,需要再重新设置 next 的 pre_entry_length 的值,而这个值需要根据 new 节点重新计算,可能会有三种情况:
- next 的 pre_entry_length 的长度刚好能够存储 new 节点的长度(都是 1 字节或都是 5 字节)。
- next 的 pre_entry_length 只有 1 个字节,而 new 的长度需要 5 个字节。
- next 的 pre_entry_length 有 5 个字节,而 new 的长度只需要 1 个字节。
第一和第三种情况直接更新 next 的 pre_entry_length 值就可以了,而第二种情况则需要为 ziplist 重新分配内存,扩展 next 的空间,这时还需要向后检查 next + 1 的 pre_entry_length 是否能够存储新的 next 的长度,就这样一直向后检查,直到有一个节点的 pre_entry_length 能够存储前一个节点的长度或者到达 ziplist 的末端 zlend 为止,这就是前面提到的连锁反应。
不过这种连锁更新的情况一般发生在新添加的节点后面有连续多个长度接近 254 (254 是 1 个字节和 5 个字节的分界线)的节点,这种概率是很小的,所以一般可以将添加操作的时间复杂度看作 O(N)。
删除节点
- 定位节点,并计算节点的空间。
1 | target start here |
- 进行内存移位,覆盖 target 的原数据,然后进行内存重分配。
1 | target start here |
- 检查 next 的后续每个节点的 pre_entry_length 能否满足前一个节点的长度,并根据情况决定是否重分配内存。
遍历
可以对 ziplist 从前往后遍历,也可以从后往前遍历。
当从前向后的遍历时,从指向节点 e1 的指针 p 开始,计算节点 e1 的长度(e1-size),然后将 p 加上 e1-size ,就将指针后移到了下一个节点 e2,如此反覆,直到 p 遇到 ZIPLIST_ENTRY_END 为止,这样整个 ziplist 就遍历完了。
1 | p + e1-size + e2-size |
当从后往前遍历的时候,从指向节点 eN 的指针 p 出发,取出 eN 的 pre_entry_length 值,然后用 p 减去 pre_entry_length ,这样就将指针移动到了前一个节点 eN-1,如此反覆,直到 p 遇到 ZIPLIST_ENTRY_HEAD 为止,这样整个 ziplist 就遍历完了。
1 | p - eN.pre_entry_length |
数据类型
对象处理机制
Redis 的命令中,对键进行处理的命令占了很大一部分,而不同的命令又需要使用不同的处理方式,为了能够识别这些命令,Redis 构建了自己的类型系统,这个系统的主要功能包括对基于 redisObject 对象的类型检查、显式多态函数以及对 redisObject 进行分配、共享和销毁。
redisObject
Redis 数据库中每个键、值,以及 Redis 本身处理的参数都表示为 redisObject。
1 | typedef struct redisObject { |
下图展示了 redisObject、type 和 encoding 的关系。
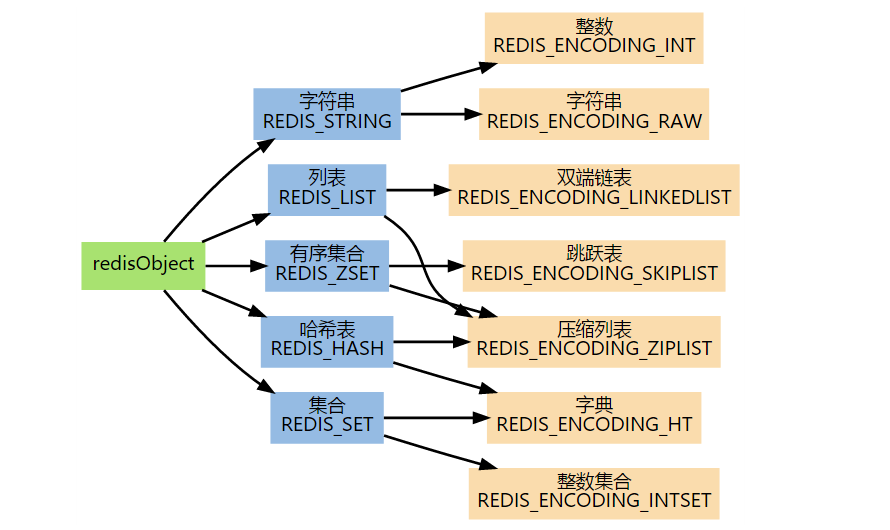
命令的类型检查和多态
有了 redisObject 的存在,Redis 在执行命令时进行类型检查和对编码进行多态操作就简单多了。
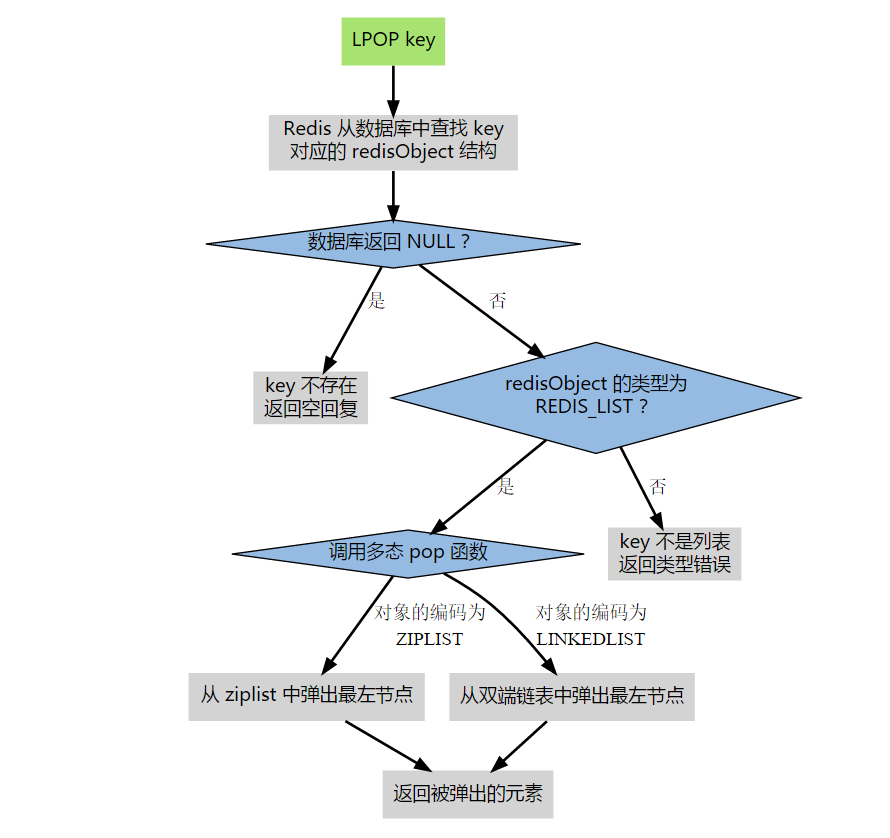
对象共享(已废弃)
Redis 中有很多对象是很常见的,比如命令的返回值 OK、ERROR 等字符,还有一些小范围的整数等,为了利用这些经常出现的对象,Redis 使用了 Flyweight 模式,通过预分配一些常见的值对象,并在多个数据结构之间共享这些对象来避免重复分配,节约部分 CPU 时间和内存。
Redis 预分配的值对象有:
- 各种命令的返回值,比如执行成功时返回的 OK,执行错误时返回的 ERROR,类型错误时返回的 WRONGTYPE,命令入队事务时返回的 QUEUED 等等。
- 包括 0 在内,小于 server.h/REDIS_SHARED_INTEGERS 的所有整数(REDIS_SHARED_INTEGERS 的值为 1000)
如果某个命令的输入值是一个小于 REDIS_SHARED_INTEGERS 的整数对象,那么当这个对象要被保存进数据库时,Redis 就会释放原来的值,并将值的指针指向共享对象。
共享对象只能被字典和双端链表这类带有指针的数据结构使用,像整数集合和压缩列表这些只能保存字符串、整数等字面值的内存数据结构,就不能使用共享对象。
需要说明的是,Redis 的作者 antirez 为了实现异步懒惰删除,已经将对象共享机制彻底抛弃了。
对象的销毁
当 redisObject 用作数据库的键或者值,而不是用作存储参数时,对象的声明周期是很长的,因为 C 语言没有自动释放内存的机制,如果靠开发人员的记忆对对象进行追踪和销毁是不太可能的。为了解决这个问题,Redis 使用了引用计数来负责维持和销毁对象。每个 redisObject 都有一个 refcount 属性用来记录引用次数,当这个属性的值为 0 时,这个 redisObject 对象以及它所引用的数据结构的内存都会被释放。
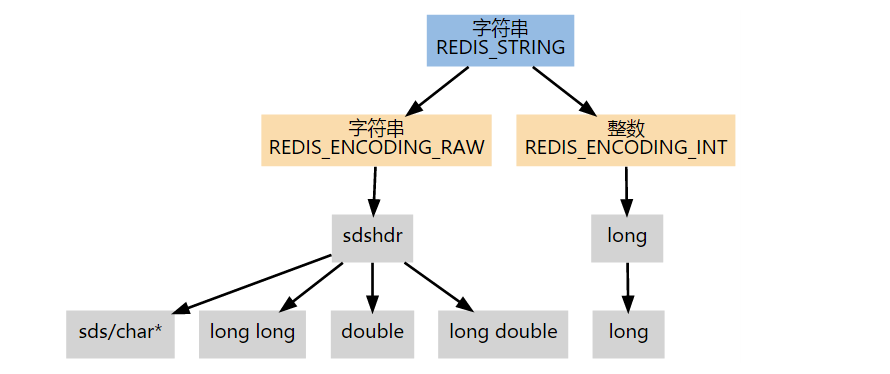
String
String 类型是二进制安全的,即可以包含任何数据,如序列化的对象、图片、视频,一个键最大可以存储 512 MB 大小的数据。
Hash
Hash 是一个键值对集合,键和值都是 String 类型的,该数据类型适合存储对象。每个 Hash 可以存储 2^32 - 1 个键值对。
Hash 根据编码的不同,有压缩列表和字典两种实现。
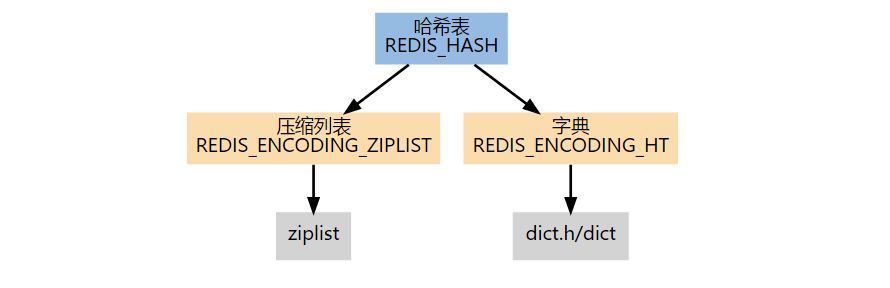
在创建空白的哈希表时,默认使用压缩列表数据结构,当满足以下任意一个条件时,结构切换成字典。
- 哈希表中某个键或某个值的长度大于 server.hash_max_ziplist_value(默认值为 64)。
- 压缩列表中的节点数量大于 server.hash_max_ziplist_entries(默认值为 512)。
List
List 是简单的字符串列表,按照插入顺序排列,同时还可以将一个元素添加到 List 的头部(左边)或者尾部(右边)。每个 List 可以存储 2^32 - 1 个元素。
List 根据编码的不同,有压缩列表和双端列表两种实现。
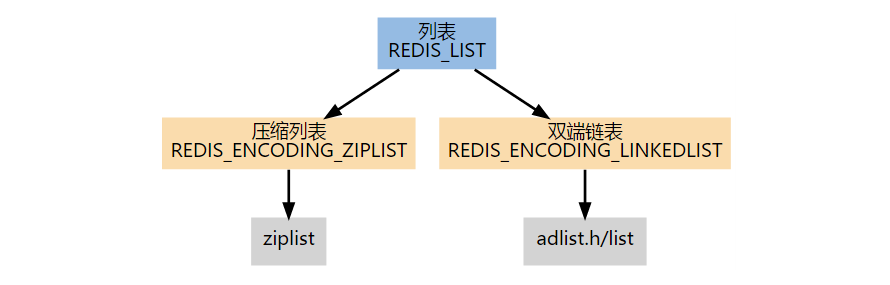
创建新列表时默认使用 REDIS_ENCODING_ZIPLIST 编码,当满足以下任意一个条件时,列表会被转换成 REDIS_ENCODING_LINKEDLIST 编码。
- 试图往列表新添加一个字符串值,且这个字符串的长度超过 server.list_max_ziplist_value(默认值为 64)。
- ziplist 包含的节点超过 server.list_max_ziplist_entries(默认值为 512)。
阻塞命令
在列表为空时执行 BLPOP、BRPOP 和 BRPOPLPUSH 这三个命令会阻塞。Redis 会将该客户端的状态设置为“正在阻塞”,并记录阻塞这个客户端的各个键,以及阻塞的超时时间。Redis 将客户端的这些信息记录到 server.db[i] -> blocking_keys 字典中,字典的键就是造成客户端阻塞的键,值是一个链表,保存了因为这个键被阻塞的客户端。这个链表形成了一个 FIFO 队列,当满足取消阻塞条件时,先被阻塞客户端的先取消阻塞状态。
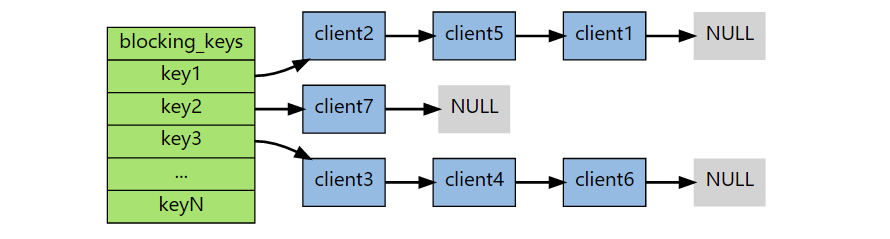
当出现以下情况之一时,客户端会从阻塞状态脱离:
- 其他客户端在造成阻塞的键上推入了新元素。
- 到达超时时间。
- 客户端强制与服务端终止连接,或者服务端实例终止。
Set
Set 是 String 类型的无序集合,集合的成员是唯一的,不能重复。Redis 中的集合是通过哈希实现的,所以添加、删除和查找的时间复杂度都是 O(1),最大成员数为 2^32 - 1。
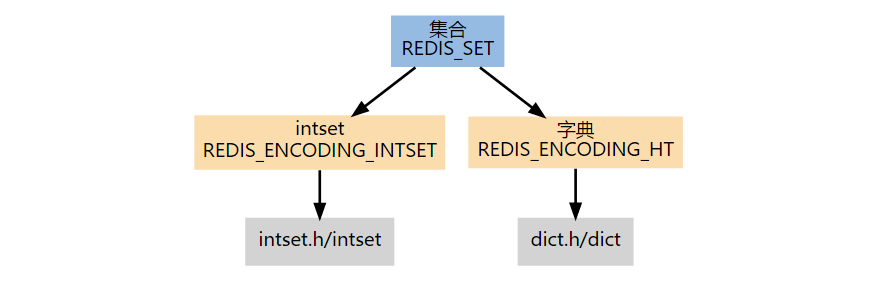
Set 根据编码的不同,有整数集合和字典两种实现。第一个添加到集合的元素,决定了创建集合时所使用的编码:
- 如果第一个元素可以表示为 long long 类型值(即它是一个整数),那么集合的初始编码为 REDIS_ENCODING_INTSET。
- 否则,集合的初始编码为 REDIS_ENCODING_HT。
如果一个集合使用 REDIS_ENCODING_INTSET 编码,当满足以下任意一个条件时,这个集合会被转换成 REDIS_ENCODING_HT 编码:
- intset 保存的整数值个数超过 server.set_max_intset_entries(默认值为 512)。
- 试图往集合里添加一个新元素,并且这个元素不能被表示为 long long 类型(即它不是一个整数)。
Sorted Set
与 Set 一样也是 String 类型的集合,且不允许重复。不同的是每个元素都会关联一个 double 类型的分数,集合中的元素通过该分数从大到小排序。其中,分数可以重复。
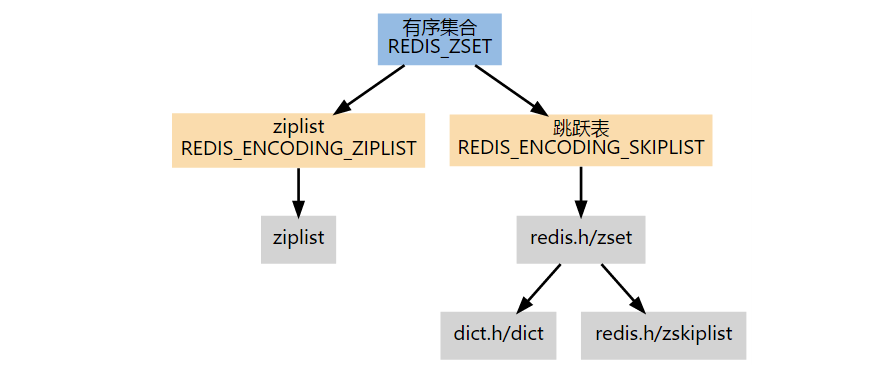
Sorted Set 根据编码的不同,有压缩列表和跳跃表两种实现。如果第一个元素符合以下条件的话,就创建一个 REDIS_ENCODING_ZIPLIST 编码的有序集:
- server.zset_max_ziplist_entries 的值大于 0(默认为 128)。
- 元素的 member 长度小于 server.zset_max_ziplist_value 的值(默认为 64)。
对于一个 REDIS_ENCODING_ZIPLIST 编码的有序集,只要满足以下任一条件,就将它转换为 REDIS_ENCODING_SKIPLIST 编码:
- ziplist 所保存的元素数量超过 server.zset_max_ziplist_entries 的值(默认值为 128)。
- 新添加元素的 member 的长度大于 server.zset_max_ziplist_value 的值(默认值为 64)。
事务
Redis 通过 MULTI、DISCARD、EXEC 和 WATCH 四个命令实现事务的功能。
Redis 的事务是将一系列命令打包,然后一次性的按顺序执行,事务在执行期间不会主动中断,只有服务端在执行完事务中所有的命令后,才会继续处理其他客户端的命令。客户端使用 MULTI 命令开启事务,在事务状态下,除了那四个事务命令外,其他的命令都不会立即执行,而是会被放入一个 FIFO 事务队列中,当使用 EXEC 命令时,服务端顺序执行事务队列中的命令,并将每个命令的执行结果顺序放入一个 FIFO 的回复队列中,在全部命令执行完毕后返回。
1 | 127.0.0.1:6379> MULTI |
Redis 的事务不可嵌套,即如果客户端已经处于事务状态,如果客户端再发送 MULTI 命令,服务端也只是简单返回一个错误,然后继续等待其他命令进入事务队列。
事务状态和非事务状态下执行命令
无论在事务状态还是在非事务状态下,Redis 命令都由同一个函数执行,所以它们共享很多服务器的一般设置,比如 AOF 的配置、RDB 的配置,以及内存限制等等。不过这两个状态下执行命令还是有区别的:
在非事务状态下的命令都是单条执行,前一个命令和后一个命令可能来自不同的客户端。而在事务状态下,命令是作为一个事务来执行的,除非事务执行完毕,否则服务端不会主动中断,也不会执行其他客户端的命令。
在非事务状态下执行命令结果会立即返回,而事务状态下则需要将所有的命令结果放入回复队列中,再作为 EXEC 命令的结果返回。
DISCARD 命令
DISCARD 命令用于取消一个事务,它清空客户端的整个事务队列,将客户端从事务状态转换为非事务状态,最后返回 OK 作为结果,说明事务已经取消。
WATCH 命令
WATCH 命令用于在事务开始之前监视任意数量的键,当调用 EXEC 执行事务时,如果任意一个被监视的键被其他客户端修改了,那么整个事务不再执行,直接返回失败。
WATCH 命令只能在客户端进入事务状态之前执行,在事务状态下发送也只会返回一个错误,不会造成整个事务的失败,也不会修改事务队列中已有的数据。
WATCH 的实现
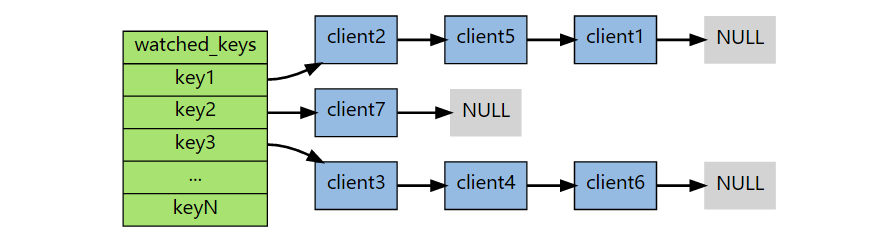
在每个代表数据库的 server.h/redisDb 结构中,都保存了一个 watched_keys 字典,字典的键是这个数据库中被监视的键,字典的值是一个链表,保存了所有监视这个键的客户端。
1 | typedef struct redisDb { |
WATCH 的触发
在对任意的数据库键空间进行修改的命令(如 FLUSHDB、SET、DEL、LPUSH、SADD、ZREM 等)执行成功后,multi.c/touchWatchedKey 函数都会被调用,它检查数据库的 watched_keys 字典,查看是否有客户端在监视已经修改的键,如果有的话,将所有监视这个已经被修改的键的客户端的 REDIS_DIRTY_CAS 选项打开。
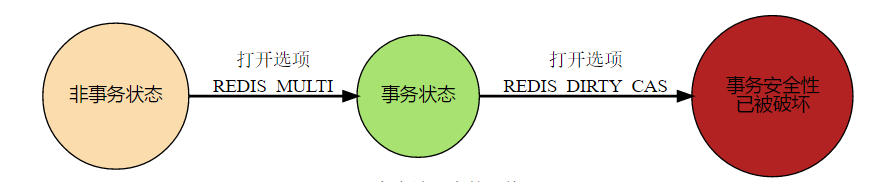
当客户端发送 EXEC 命令时,服务端会对客户端的状态进行检查:
- 如果客户端的 REDIS_DIRTY_CAS 选项已经被打开,说明客户端监视的键至少有一个已经被修改了,事务的安全性已经被破坏。服务端会放弃执行这个事务,并返回一个空的回复表示事务执行失败。
- 如果 REDIS_DIRTY_CAS 没有打开,则说明所有被监视的键都安全,服务端正式执行事务。
扩展
Redis 为什么这么快?
- 完全基于内存,绝大部分操作都是纯粹的内存操作。
- 数据结构简单,同时对数据的操作也简单。
- 采用单线程,避免了不必要的上下文切换,也不会因为多线程下为了线程安全而加锁导致性能损耗。
- 使用 I/O 多路复用,可以让单个线程能够更高效的处理更多的连接请求,相对来说减少了网络 IO 的时间消耗,同时这也是 Redis 能够承受很大的客户端并发量的原因。
为什么 Redis 是单线程的?
首先需要强调的是,我们一直提到的 Redis 是单线程的是指 Redis 在处理我们的网络请求时只使用一个线程来处理(I/O 多路复用),同时大部分的内存操作也是单线程的,实际上一个 Redis 实例在运行时肯定使用了不止一个线程。这里引用官网的一段解释:
Redis is single threaded. How can I exploit multiple CPU / cores?
It’s not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
However, to maximize CPU usage you can start multiple instances of Redis in the same box and treat them as different servers. At some point a single box may not be enough anyway, so if you want to use multiple CPUs you can start thinking of some way to shard earlier.
You can find more information about using multiple Redis instances in the Partitioning page.
However with Redis 4.0 we started to make Redis more threaded. For now this is limited to deleting objects in the background, and to blocking commands implemented via Redis modules. For the next releases, the plan is to make Redis more and more threaded.
摘取其中的重点就是,限制 Redis 使用的瓶颈通常并不是 CPU,而是内存和网络,Redis 在 4.0 版本以后使用了多线程在后台删除对象,其他大部分操作还是只使用了一个线程。
这里给出了一个不使用多线程的原因,就是当前的瓶颈并不在于 CPU 而在于内存和网络,那么如果使用多个线程去操作内存数据又会带来哪些问题呢?
我们知道多线程执行任务有个致命的问题就是线程切换,线程在获得 CPU 执行权执行一段时间后,可能其他线程获得了执行权,此时该线程需要释放执行权,而任务很可能还没有执行完,因此需要保存线程执行的上下文,以便后续该线程的恢复。这个操作需要消耗大量的 CPU 执行时间,事实上,这也是操作系统中消耗最大的操作。另外,如果线程切换是跨核上下文切换,则会引起缓存丢失,结果就需要访问本地内存,这个代价是更高的。
Redis 采用单个线程绑定一块内存,针对这部分内存数据的读写都是在一个 CPU 上完成的,不存在上下文切换的开销,在只有内存读写时效率最高。并且需要知道的是,Redis 的性能瓶颈不是 CPU,而是内存大小和网络带宽,既然 CPU 不会成为瓶颈,而使用多线程又会增加复杂度,因此使用单线程也就顺理成章了。
总结:Redis 目前使用单线程和 I/O 多路复用处理客户端的连接,使用单线程处理内存操作,只有后台删除使用了多线程,原因是当前的瓶颈并不在于 CPU 而在于内存和网络,如果使用多线程去处理内存操作,不光增加了复杂度,也会因为线程的上下文切换增加 CPU 的开销。
Redis 与 I/O 多路复用
Redis 没有使用 Libevent 而是选择实现了自己的 Event Library,因为 Libevent 为了通用性编写了过多的代码,并且牺牲了在特定平台的许多特性。
如何利用多核优势
可以在多核机器上启动多个 Redis 实例组成主从或者集群,然后通过内核绑定程序(比如 taskset、numactl)将实例与内核进行绑定,即一个内核绑定一个实例,这样可以避免内核分配不均,从而避免线程争用和跨核上下文切换。
未来为什么要引入多线程
在 2019 年的 2 月份,Redis 的作者 antirez 在他的博客上发表了一篇题为:An update about Redis developments in 2019 的文章,其中提到了 Redis 在将来可能使用多线程的几种方式。
对于目前单线程的 Redis 来说,性能瓶颈主要在于网络 I/O 的消耗,读写网络数据的 read/write 系统调用在 Redis 执行期间占用了大量的 CPU 时间,如果把网络读写改为多线程的方式可以充分利用多核优势,提高网络 I/O 性能。
在即将到来的 Redis 6.0 中,Redis 将会引入多线程支持。与 Memcached 这种从网络 I/O 处理到数据访问的多线程实现模式不同,Redis 的多线程部分只用于处理网络数据的读写和协议的解析,真正执行命令的仍然是单线程,这样可以避免很多并发问题。其中,主线程负责接收建立连接的请求,在读事件到来时放到全局等待读队列中,在主线程处理完读事件之后,会将这些读请求分配给 I/O 线程,然后主线程忙等,当所有的 I/O 线程将请求数据读取并解析完成后,主线程负责执行所有的命令并清空队列。
参考
《Redis 设计与实现》