SQL 中 in 与 exists
数据库使用的是 MySQL,版本为 5.7.20。有两张基础表 user 和 list,表结构如下:
1 | create table user |
1 | create table list |

其中,list 表中的 user_id 对应 user 表中的 id。user 表共有 100 万条数据,list 表只有 4 条数据。
in
1 | SELECT |
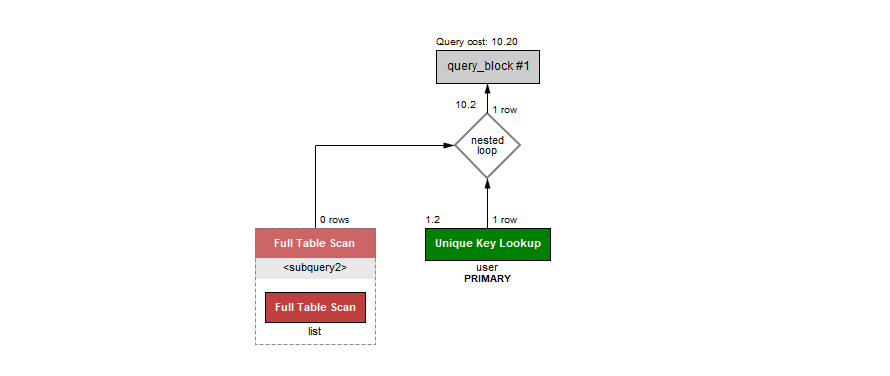
在查询时,首先执行子查询中的 FROM list 进行全表扫描并物化,然后使用物化后的表与 user 表进行连接查询。整个过程耗时为 62 ms(execution:31 ms,fetching:31 ms)。

可以通过执行计划查看执行的过程:
1 | EXPLAIN |

exists
1 | SELECT |
以上 SQL 的执行结果和使用 in 时一致。但是两者的执行过程完全不一样,可以先查看执行计划来分析这个过程。

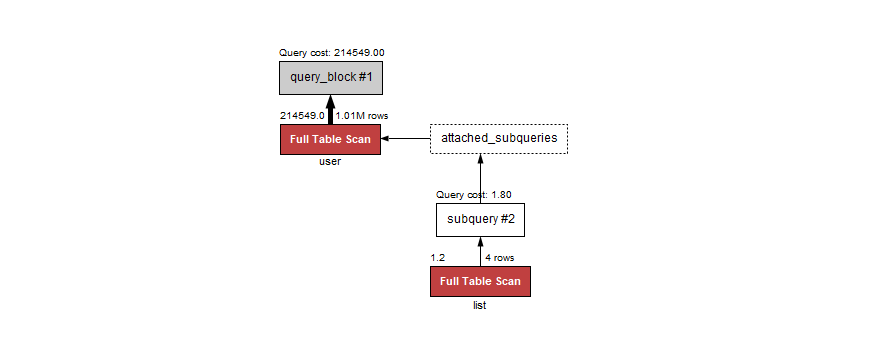
执行计划中指出以上查询需要执行两个过程,首先执行 id 为 2 的过程,根据 type 为 ALL 判断括号中的子查询需要进行全表扫描,接下来要执行子查询的 WHERE 条件,但是根据 select_type 的值为 DEPENDENT SUBQUERY 判断括号中的子查询需要依赖外表的查询结果,所以接下来就执行 id 为 1 的过程,对 user 表进行全表扫描,接下来对外表的查询结果进行逐条 loop,每次 loop 执行子查询的 WHERE 条件,满足条件有结果返回则为 true,最终外表的 SELECT * 将满足条件的结果返回。整个过程耗时为 2 s 579 ms(execution:2 s 564 ms,fetching:15 ms)。
总结
通过以上实例可以看出,并不能一味的使用 exists 替换 in。在外表数据量较大,而内表数据量较小,同时外表使用的查询条件为索引时,使用 in 的效率很高。在外表数据量较小,而内表数据量较大时可以使用 exists 来替换。当两张表的数据量相当时,使用 in 和 exists 的差别并不大。