深入 LinkedHashMap
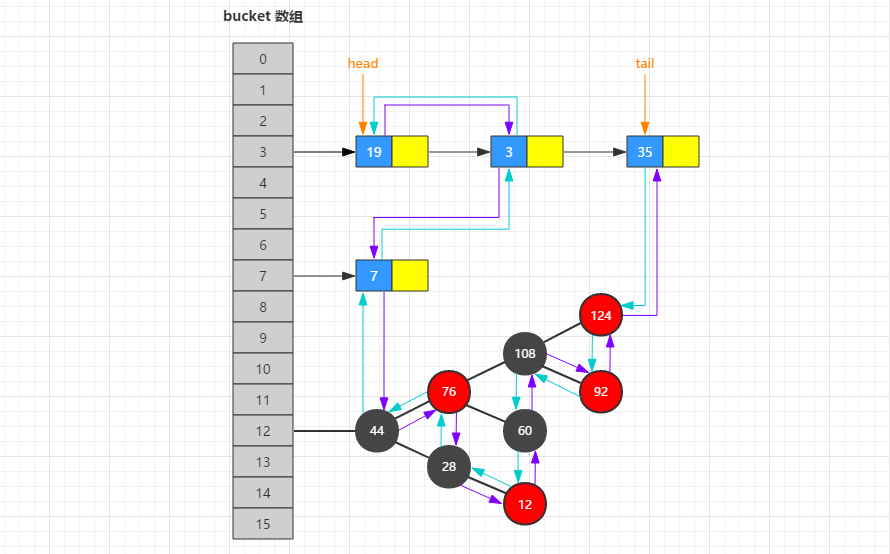
LinkedHashMap 继承自 HashMap,在 HashMap 的基础上,通过维护一条双向链表,解决了 HashMap 遍历顺序与插入顺序不一致的问题,除此之外还对访问顺序提供了支持,这在一些场景下是很有用的,比如缓存。
节点
其实 LinkedHashMap 的节点并没有什么特别的地方,因为继承自 HashMap,节点类型继承自 HashMap 也是可以理解的。需要说明的是 HashMap 的树节点类型。
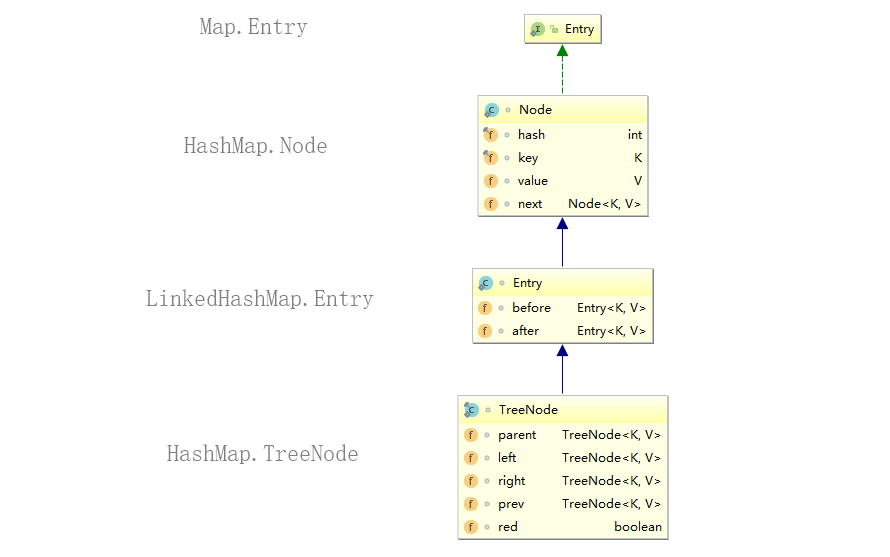
LinkedHashMap 在 HashMap 节点的基础上又增加了两个属性 before 和 after,通过这两个属性就可以维护一条按照插入顺序排列的双向链表。但是 HashMap 的树节点继承自 LinkedHashMap 的节点就有点奇怪了,我们在使用 HashMap 的红黑树时,并不需要树节点具有组成双向链表的能力,这样做肯定会造成空间上的浪费。在 HashMap 的源代码中这样一段注释:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD. And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used.
大致的意思是 TreeNode 对象的大小大约是常规 Node 对象的 2 倍,所以我们仅在桶数组中包含足够多的键值对时才使用(TREEIFY_THRESHOLD 的限制)。当桶中的键值对数量变少时(删除元素或者是扩容),TreeNode 会转换成 Node。用户在使用分布均匀的 hashCode 时,红黑树是很少使用的。
通过这段注释我们可以了解到,只要 hashCode 的实现不太糟糕,Node 是很少会转换成 TreeNode 的,并且如果 TreeNode 继承自 Node,当它想具备组成双向链表的能力时,就需要 Node 去继承 LinkedHashMap.Entry,这个时候才是得不偿失的。
插入元素
由于继承自 HashMap,因此插入的逻辑大部分是一样的。
1 | public V put(K key, V value) { |
删除元素
1 | public V remove(Object key) { |
访问顺序
LinkedHashMap 中维护了一个成员变量 accessOrder,默认值为 false,可以在调用构造方法时指定。当它为 true 时,LinkedHashMap 将会按照元素访问的顺序来维护链表;当它为 false 时,会按照元素插入(添加)顺序维护链表。按照元素访问顺序维护链表其实就是在我们调用 get()、getOrDefault() 等方法时将这些方法访问的节点移动到链表的尾部即可。
1 | public V get(Object key) { |
遍历的效果如下:
1 | public static void main(String[] args) { |
1 | key=India value=Delhi |
LRU 缓存实现
在插入元素的代码中有一段执行了一个回调方法 afterNodeInsertion(),实现的是在元素插入后执行的操作,该方法在 LinkedHashMap 中的实现为:
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
当 accessOrder 设置为 true 时,LinkedHashMap 中的头节点就变成了最近最少使用的节点,afterNodeInsertion() 方法删除的就是头节点,因此可以通过继承 LinkedHashMap 来实现一个简单的 LRU 缓存。在重写 removeEldestEntry() 方法时,可以根据当前节点的数量来决定是否要删除最近最少使用的节点,也可以根据节点的存活时间等其他方式来决定。
下面是通过继承 LinkedHashMap 实现的一个简单的 LRU 策略的缓存。
1 | public class SimpleCache<K, V> extends LinkedHashMap<K, V> { |