Shell 学习
在计算机科学中,Shell 俗称壳程序,用来区别于操作系统内核程序。Shell 首先是 UNIX/Linux 下的脚本编程语言,它是解释执行的,无需提前编译。同时它也是一个程序,为使用者(用户或其他应用程序)提供与内核交互的操作界面,它接收用户命令,然后通过命令解析调用相应的应用程序。
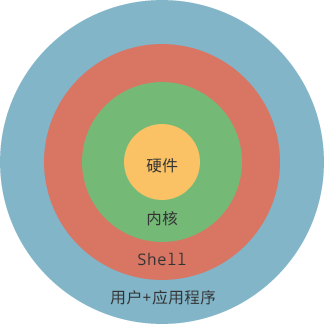
广义上的 Shell
广义上讲,只要能够为使用者提供与内核交互的都可以认为是 Shell,因此 Shell 可以分为两大类:图形界面 Shell(GUI Shell)与命令行 Shell(CLI Shell)。
图形界面 Shell 应用最广泛的要属 Windows 系列操作系统了,还有 Linux 的 X window manager,以及功能更加强大的 CDE、GNOME、KDE 等。
命令行 Shell 主要包括 MS-DOS 系统下的命令行,Windows NT 下的 cmd.exe,支持 .NET Framework 的 Windows NT 系统下的 Windows PowerShell 以及 UNIX/Linux 系统下的 sh/bash/csh 等。
我们习惯性地把微软旗下所有的操作系统都叫做 Windows,但其实它们是有很大区别的。最初的 Windows 只是一个运行在 MS-DOS 下的图形界面,从 Windows 1.x/2.x/3.x 一直发展到 Windows 9x/ME,期间从 Windows 95 开始,微软划时代地推出了混合的 16 位 / 32 位操作系统,这个时候的 Windows 虽然图形界面是 32 位的,但是操作系统还是 DOS,仍然能够运行 16 位的 DOS 程序。后来微软放弃了 MS-DOS,推出了另一条产品线 Windows NT。早期的 Windows NT 是一种纯 32 位操作系统,这个时候的操作系统除了在加电启动时是运行在 16 位模式(实模式),其他时候都是运行在 32 位模式(保护模式)。虽然 Windows NT 已经告别了 DOS,但还是可以通过模拟来运行 DOS 程序,比如在 Windows 8 中运行 DOS 程序会提示安装 NTVDM 来模拟 DOS 程序运行时的环境。但是由于 64 位的 Windows 不支持 NTVDM,所以也就没有办法运行 DOS 程序了。
那么我们平常口中说的在 Windows NT 中运行 DOS 命令又是什么意思呢?因为在 MS-DOS 中是通过一系列的命令与内核交互,早期和中期的 Windows 都可以执行这些命令,到了 Windows NT,这些命令的使用方式并没有发生变化,于是就沿用了执行 DOS 命令这一说法了,而实际上此时在执行这些命令时使用的只是 Windows NT 提供的一个叫 cmd.exe 的命令行辅助工具,跟 DOS 已经没有关系了。
Linux 下的 Shell
在 Linux 下有很多不同的 Shell,常见的有 sh、bash、csh、tcsh、ash 等,sh 已经被 bash 代替,/bin/sh 往往是指向 /bin/bash 的符号链接。我们可以通过 cat /etc/shells 命令来查看当前系统下可以使用的 Shell 有哪些。
1 | $ cat /etc/shells |
进入 Shell
一种进入 Shell 的方法是退出图形界面模式,进入控制台模式。现代的 Linux 操作系统在启动时会自动创建几个虚拟控制台(Virtual Console,在 Linux 系统内存中运行的虚拟终端),其中一个供图形桌面程序使用,其他的保留原生控制台的样子。例如:CentOS 在启动时会创建 6 个虚拟控制台,分别对应快捷键 Ctrl + Alt + Fn(n=1,2,3,4,5,6),其中图形界面模式对应 Ctrl + Alt + F1。
另一种方式就是使用 Linux 桌面环境提供的终端模拟包(Terminal emulation package),也就是我们常说的终端(Terminal),这样就可以在图形桌面中使用 Shell。
Bash Shell 的操作环境
在登录主机时,屏幕会显示一些说明文字,比如告知我们 Linux 的版本等信息。我们习惯的环境变量、命令别名等在登录后也会被自动配置出来。这些都是 bash 在启动时通过读取环境配置文件来初始化的。
命令搜寻顺序
一个命令下达,它的搜寻顺序如下:
- 以相对或者绝对路径执行命令,比如
/bin/ls或者./ls。 - 以 alias 找到该命令执行。
- 由 bash 内建的命令来执行。
- 通过
$PATH这个变量值的顺序找到第一个命令来执行。
bash 的环境配置文件
在系统中有一些环境配置文件,在 bash 启动时会去读取这些文件来初始化 bash 的操作环境。而 shell 又有 login shell 和 non-login shell,不同的 shell 读取的配置也是有区别的。
login shell
login shell 指的是在获取 bash 时进行了完整的登录流程。比如,由 tty1 ~ tty6 登录,通过输入用户名和密码成功进入 bash。
一般来说,login shell 只会读取两个文件,一个是 /etc/profile,它是系统整体的配置文件;另一个是用户的配置文件。
在 /etc/profile 文件中,它会根据用户的 UID 去配置 PATH、MAIL、USER、HISTSIZE 等变量的值,然后设置用户的 umask 的值,最后读取 /etc/profile.d/*.sh 中的一系列文件。
在读取完系统配置文件后,接下来就会去读取用户的配置文件。用户的配置文件按照读取的顺序分别为:~/.bash_profile、~/.bash_login 和 ~/.profile,login shell 只会读取其中的某一个。如果在用户目录下存在 .bashrc 文件,则会读取该文件。
source
由于配置文件的内容是在取得 login shell 的时候才会读取,因此如果后续修改配置文件,就需要注销后重新登录才能生效。如果不想重新登录,可以使用 source 命令重新读取配置文件。
1 | # 重新读取配置文件 |
non-login shell
non-login shell 是指在获取 bash 时没有进行登录流程。比如在图形桌面中使用 Ctrl + Alt + T 启动的 shell 就是 non-login shell,在使用 su 命令切换用户时,不加 --login 参数(使用 su - 用户名 或者 su --login 用户名 的方式获取到的是 login shell)获取到的也是 non-login shell。
一般来说,non-login shell 只会读取 ~/.bashrc,在该文件中除了会应用使用者的个人配置外,还会呼叫外部配置文件 /etc/bashrc(Red Hat 系统特有的),然后根据用户的 UID 设置 umask 和 PS1 的值,同时还会读取 /etc/profile.d/*.sh 中的一系列文件。
其他配置文件
还有一些配置文件也会影响 bash 环境,比如 ~/.bash_logout 就记录了当注销 bash 后系统将会执行的动作,默认情况下只是清除屏幕信息,当然我们可以自定义其他的动作。
内建命令
bash 有很多的内建命令,这些命令可以在 bash 中直接使用。通常来说,内建命令会比外部命令执行得更快,执行外部命令时不但会触发磁盘 I/O,还需要 fork 出一个单独的进程来执行,执行完成后再退出。而执行内建命令相当于调用当前 Shell 进程的一个函数。要判断一个命令是不是内建命令,一种方式是通过 Linux 的联机帮助文件查看,比如使用 man cd 查看 cd 这个命令的说明文档。还有一种方式是通过 type 这个内建命令查询。比如 ls 命令,则可以使用 type ls 来查看该命令是否是内建命令。
命令替换
命令替换是指将命令的输出结果作为值赋给某个变量,在写法上有两种方式,一种是使用反引号,一种是使用 $()。
1 | DATE_1=`date` |
如果被替换的命令的输出内容包括多行(即有换行符),或者含有多个连续的空白符,那么在输出变量时应该将变量用双引号包围,否则系统会使用默认的空白符来填充,这会导致换行无效,以及连续的空白符被压缩成一个,比如:
1 | # 执行 ls -l |
需要注意的是,使用 $() 相对清晰,且支持嵌套,但是 $() 仅在 bash 环境下有效。而反引号由于看起来与单引号类似,可能会对使用者造成困扰,但是反引号可以在多种 shell 环境中使用。
命令别名
alias 命令用来给命令创建别名,如果直接下达该命令不带任何参数,则会列出 shell 环境中使用的所有别名。
1 | # 设置别名 |
如果想要别名永久生效,需要把别名写入到用户目录下的 .bashrc 文件中。
历史命令
历史命令记录的笔数与环境变量 HISTFILESIZE 的配置有关。
1 | # 列出当前内存中的所有 history 记录 |
资源限制
系统的可用资源是有限的,如果不限制用户和进程对系统资源的使用,则很容易造成资源耗尽。使用 ulimit 命令可以控制进程对可用资源的访问。
默认情况下 Linux 系统的各个资源都做了软硬限制,其中硬限制的作用是控制软限制(即软限制不能高于硬限制)。
1 | # 查看当前系统的软限制 |
1 | # 设置最大可以打开的文件数 |
使用 ulimit 命令可以修改资源的限制,但是当用户注销后会失效。如果想永久生效,则需要修改 /etc/security/limits.conf 文件。
变量
在 bash 中定义变量不需要指明变量的类型,每个变量的值都是字符串,即使在赋值时没有使用引号,它们也会被视为字符串。当然,在实际解释执行的过程中,如果需要进行算术运算,则会自动将值转化为整数(bash 不支持浮点类型的运算,除非借助于第三方工具)。
变量声明及赋值
变量命名时只能使用字母、数字和下划线,首字符不能以数字开头,同时不能使用 bash 里的关键字,比如:
1 | # 定义变量 your_name |
变量的测试与替换
有时候我们需要判断某个变量是否存在,并根据判断的结果进行选择性地赋值。
| 参数设置表达式 | str 没有设置 | str 为空字符串 | str 为非空字符串 |
|---|---|---|---|
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr, var=expr | str 不变, var= | str 不变, var=$str |
| var=${str:=expr} | str=expr, var=expr | str=expr, var=expr | str 不变, var=$str |
| var=${str?expr} | expr 输出至 stderr | var= | var=$str |
| var=${str:?expr} | expr 输出至 stderr | expr 输出至 stderr | var=$str |
使用变量
使用一个定义过的变量,只要在变量名前面加上 $ 符号即可。
1 | your_name="Saber" |
变量名外可以不使用花括号,加上花括号是为了帮助解释器识别变量的边界,比如:
1 | for skill in Ada Coffe Java;do |
只读变量
使用 readonly 命令可以将变量定义为只读的,只读变量的值不能被修改。
1 |
|
删除变量
使用 unset 命令可以删除变量,已经删除的变量无法再次使用,该命令无法删除只读变量。
1 | myUrl="https://nekolr.com" |
变量的作用域
bash 中的变量根据作用范围划分共有三种,包括局部变量、全局变量和环境变量。
- 局部变量,只能在函数内部有效。使用
local命令定义局部变量,该命令只能在函数中使用。如果在函数中没有使用该命令定义变量,那么变量会如同在 JavaScript 里没有使用var定义变量一样是全局变量。 - 全局变量,在当前 shell 进程中都可以使用,一般在 shell 中定义的变量,默认都是全局变量。
- 环境变量,可以在当前进程或者子进程中使用。
环境变量
全局变量只能在当前 shell 进程中使用,如果使用 export 命令将它导出,那么它就可以在所有的子进程中使用了,这时它也就变成了环境变量。
当登录 Linux 并取得一个 bash 之后,该 bash 就作为一个独立的进程存在。接下来在这个 bash 底下所下达的任何命令都会执行成为这个 bash 的子程序。子程序会继承父程序的环境变量,但是不会继承父程序的自定义变量。
需要注意的是,在父 shell 中创建的环境变量可以在所有的子程序中使用,但是如果使用终端创建一个新的 shell,那么它就不是当前 shell 的子进程,当前 shell 的环境变量对它也就无效了。
我们可以使用 env 命令查看当前 shell 环境下的所有环境变量,比如以下就是常见的环境变量。
| 变量 | 含义 |
|---|---|
| HOME | 表示用户的根目录。当我们使用 cd 或者 cd ~ 命令时,取用的就是这个变量。 |
| SHELL | 表示当前 shell 环境使用的是什么 shell 程序,比如 Linux 默认使用的是 /bin/bash。 |
| 当我们使用 mail 这个命令收信时,系统会去读取的邮件信箱文件。 | |
| PATH | 运行文件时搜寻的路径,目录与目录中间以冒号分隔。 |
| LANG | 表示系统使用的语言。一般默认是 en_US.UTF-8 |
通过 export 变量名 的形式导出的是临时环境变量,当 shell 会话注销后会失效。如果想永久生效,一种是对当前用户永久生效,这种需要在当前的用户目录下的 .bash_profile 文件中新增变量并导出。另一种是对所有用户永久生效,这种则需要在 /etc/profile 文件中新增变量并导出。最后再使用 source 文件名 的方式通知当前 shell 读取并执行修改后的文件,使配置立即生效。
bash 操作接口有关的变量
bash 中不光有环境变量,还有一些与 bash 操作接口有关的变量,以及用户自定义的变量,这些变量可以使用 set 命令查看,其中有几个比较重要的变量。
PS1,当我们每次按下 [Enter] 按键去运行某个命令后,最后要再次出现提示字符时,就会主动去读取这个变量值。每个 distributions 的 bash 默认的 PS1 变量内容可能有些许的差异。举例来说,CentOS 下 PS1 的值为:'[\u@\h \W]\$ ',对应的命令提示符可能为:[root@VM_59_13_centos ~],具体可以通过 man bash 命令查找这些符号的说明。
$ 代表的是当前这个 shell 的进程号,亦即是所谓的 PID (Process ID)。使用 echo $$ 命令可以查看当前 shell 的 PID。
? 代表的是上一个运行的命令所回传的值。当我们运行某些命令时,这些命令都会回传一个运行后的代码。一般来说,如果成功的运行该命令,则会回传一个 0 值;如果运行过程发生错误,就会回传错误代码,一般以非为 0 的数值表示,比如:
1 | $ ehco $SHELL |
特殊变量
| 变量 | 含义 |
|---|---|
$0 |
当前脚本的文件名。 |
$n (n≥1) |
传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是 $1,第二个参数是 $2。 |
$# |
传递给脚本或函数的参数个数。 |
$* |
传递给脚本或函数的所有参数。 |
$@ |
传递给脚本或函数的所有参数。当变量被双引号包含时,$@ 与 $* 稍有不同。比如传递了 3 个参数,那么对于 "$*" 来说,这 3 个参数会合并到一起形成一份数据,它们之间是无法分割的;而对于 "$@" 来说,这 3 个参数是相互独立的,它们是 3 份数据。 |
$? |
上个命令的退出状态,或函数的返回值。0 表示没有错误,其他任何值表示有错误。 |
$$ |
当前 Shell 进程 ID。对于 Shell 脚本来说就是这些脚本所在的进程 ID。 |
使用一个例子说明这些参数。编写脚本,并保存为 test.sh:
1 |
|
接下来运行该脚本。
1 | $ chmod +x ./test.sh |
字符串
Shell 中的字符串可以用单引号或者是双引号表示,但是这两种方式是有区别的。
使用单引号字符串,字符串里的内容都会原样输出,在里面使用变量是无效的;而使用双引号,则可以在里面使用变量,同时也支持转义。
1 | your_name='Alice' |
拼接字符串
1 | your_name='Alice' |
获取字符串长度
1 | your_name="Alice" |
字符串切片
具体的格式为:${string: start: length}。这里需要注意的是,有从左或者从右两种计数方式,如果从左计数,则从 0 开始;如果从右开始计数,则从 1 开始。不管从左还是从右计数,截取始终是从左向右。
1 | your_name="Alice" |
复杂的,还可以根据指定的子串进行截取。
| 表达式 | 说明 |
|---|---|
| ${变量#关键词} | 若变量内容从头开始的数据符合关键词,则将符合的最短数据删除 |
| ${变量##关键词} | 若变量内容从头开始的数据符合关键词,则将符合的最长数据删除 |
| ${变量%关键词} | 若变量内容从尾向前的数据符合关键词,则将符合的最短数据删除 |
| ${变量%%关键词} | 若变量内容从尾向前的数据符合关键词,则将符合的最长数据删除 |
| ${变量/旧字符串/新字符串} | 若变量内容中包含旧字符串,则变量中第一个旧字符串会被新字符串取代 |
| ${变量//旧字符串/新字符串} | 若变量内容中包含旧字符串,则变量中全部的旧字符串会被新字符串取代 |
1 | url="https://nekolr.com" |
大小写转换
1 | your_name='Alice' |
数组
bash 支持一维数组,但不支持多维数组,数组的大小没有限制。
定义数组
1 | arr=("Java" "Python" "Ruby" "Go") |
定义数组无需给每个元素赋值,可以只给特定位置的元素赋值。
1 | # 数组的长度为 3 |
读取数组
1 | arr=("Java" "Python" "Ruby" "Go") |
获取数组长度
获取数组长度的方法与获取字符串长度的方法一样。
1 | arr=([3]="Java" [5]=19 [11]=33) |
删除数组元素
在 shell 中使用 unset 删除数组元素。
1 | arr=([3]="Java" [5]=19 [11]=33) |
数组拼接
1 | arr1=(23 55) |
变量宣告
bash 中的变量默认都是字符串类型,如果需要非字符串类型的变量,就需要通过 declare 或 typeset 命令进行变量宣告,即声明变量的类型。
1 | # 定义数组 |
键盘读取
使用 read 命令能够读取键盘输入的内容。
1 | # 参数 p 后面跟着提示信息 |
数据流重导向
数据流重导向就是将某个命令执行后要出现在屏幕上的数据(standard output 和 standard error output)传输到其他地方,例如:文件、打印机等。
标准输入和输出
| 名称 | 代码 | 使用 |
|---|---|---|
| 标准输入(stdin) | 0 | 使用 < 或 0< 覆盖,<< 或 0<< 追加。 |
| 标准输出(stdout) | 1 | 使用 > 或 1> 覆盖,>> 或 1>> 追加。 |
| 标准错误输出(stderr) | 2 | 使用 2> 覆盖,2>> 追加。 |
1 | # 使用一般用户账号搜寻 /home 底下是否有 .bashrc 文件 |
这里需要注意的是,cmd > file 2>&1 中的 & 表示重定向的目标不是某个文件,而是一个文件描述符,换句话说就是 2>&1 表示将 stderr 重定向到文件描述符为 1 的文件(即 /dev/stdout,这个文件就是 stdout 在文件系统中的映射)中,而 &> file 是另一种写法。
垃圾桶
如果提前知道有错误信息会输出,想要将错误信息忽略掉或者不存储时,可以使用 /dev/null 文件。该文件是一个特殊的文件,写入到它的内容都会被丢弃,如果尝试读取它的内容,那么什么也读不到。
1 | # 将错误的数据丢弃,屏幕只会显示正确的信息 |
命令运行的判断依据
很多时候我们想要一次运行很多条命令,除了使用 shell 脚本,另一种方式就是使用多重命令。
在不用考虑命令的相关性时,连续下达命令。使用 cmd;cmd 的形式,比如:
1 | # 在关机前执行两次同步写入磁盘 |
如果一个命令的运行需要另一个命令先执行,则可以使用 cmd && cmd 或者 cmd || cmd 的形式下达命令。
| 命令 | 说明 |
|---|---|
| cmd1 && cmd2 | 如果 cmd1 运行完毕且正确执行(命令回传 $? 的值为 0),则执行 cmd2;否则不执行 cmd2 |
| cmd1 || cmd2 | 如果 cmd1 运行完毕且正确执行,则 cmd2 不执行;否则执行 cmd2 |
管线命令
如果命令输出的内容必须经过处理才能得到我们想要的格式,那么此时就需要用到管线命令(pipe)。需要注意的是,管线命令与连续下达命令是不一样的。
管线命令使用的是 | 这个界定符号,它只能处理前面的命令传递过来的 stdout。每个管线后面的第一个数据必定是命令,而且这个命令必须能够接受 stdin 的数据。比如:less、more、head、tail 等命令可以接受 stdin 的数据,而 ls、cp、mv 等就不是管线命令了。
cut
cut 命令主要用来切割文件内容。
1 | # 参数 d 代表的是分隔符,参数 f 代表的当使用分隔符切割后的第几段 |
grep
grep 命令主要用来筛选匹配的数据。
1 | # 根据关键字筛选 |
sort
sort 命令主要用来对数据进行排序。
1 | # 按字典顺序排序 |
uniq
uniq 命令主要用来去重。
1 | # 排序完成后,将重复的数据仅显示一份 |
wc
wc 命令主要用来统计文件的行数、字符数等信息。
1 | # 列出文件中有多少行、多少字(英文单字)、多少字符 |
tee
tee 命令会同时将数据流发送到文件和屏幕,而输出到屏幕的,其实就是 stdout,因此后面可以继续使用管线命令。
1 | # 将 last 命令的输出保存一份到文件中 |
tr
tr 命令可以用来删除或替换一段数据中的某些内容。
1 | # 将所有内容小写转大写 |
col
col 命令可以用来将内容中的 Tab 转换为对等的空格。
1 | # 将文件中的 Tab 转换为空格 |
参考
《鸟哥的Linux私房菜》