RPC 概述
RPC,也就是远程过程调用(Remote Procedure Call),通俗的解释就是通过网络来请求服务,而不需要了解底层网络技术的协议和细节。可能就是因为这个通俗的解释,造成很多人混淆了 HTTP 与 RPC。
首先需要明确的是 HTTP 与 RPC 从严格意义上讲不是并行的概念,虽然它们的最终目的都是通过网络来请求服务,但是 HTTP 只是一种工作在应用层的简单的请求-响应协议,而 RPC 更多的是一种概念、编程模式或者说是框架。维基百科上对于 RPC 的定义更为严谨,它说:RPC 是指计算机程序在运行过程中导致子进程在不同的地址空间(通常是指不同的机器)运行时,其编码方式与在本地的过程调用相同,即无论子进程(子程序)正在执行的是本地程序还是远程程序,程序的编码基本相同。比如在 Java 中,使用 Dubbo 获取远程业务类时与在本地使用该类的方式是一样的。
1 |
|
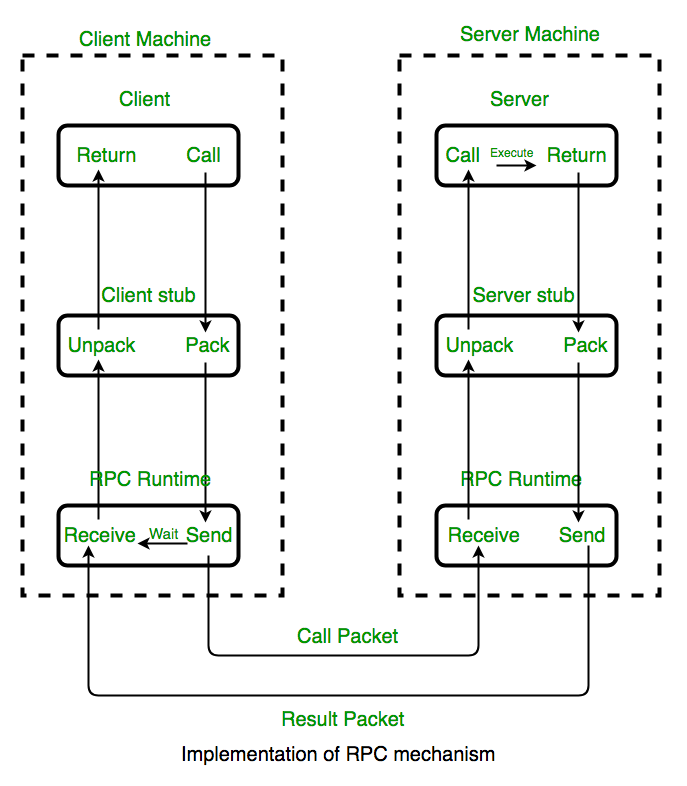
RPC 是进程间通信(IPC,Inter process communication)的一种形式,因为不同的进程具有不同的地址空间,与之相对的是本地过程调用(LPC,Local Procedure Call)。要实现一个 RPC 框架,首先需要解决的就是网络传输,也就是通信的问题。通信协议可以选择使用 HTTP,比如 Google 开源的 gRPC 就是使用的 HTTP/2 作为通信协议;也可以选择在 TCP 的基础上定制私有协议,比如 Dubbo 使用的 Dubbo 协议就是在 TCP 协议的基础上封装了自己的报文格式。
当我们解决了通信问题后,就可以开始调用远程方法了,那么我们怎么知道要调用哪个方法呢?我们可以很容易的在本地调用本地的某个对象的某个方法,但是在本地调用远程的方法时就不会这么简单了,因为这两个应用,具体来说是这两个进程的地址空间完全不同。所以此时需要解决的问题是寻址问题,也就是要找到具体应该调用哪个主机的哪个端口的哪个方法。比如在 RMI 中,需要提供一个 RMI Registry 来注册服务的地址,然后通过这个地址就可以调用指定的方法。
假设我们已经解决了寻址问题,但是方法不可能都是空参数的方法啊,如果方法需要传参怎么办?在本地调用时,我们只需要把参数压到栈里,然后让函数到栈里读取就可以了。但是在远程调用的过程中,客户端跟服务端是不同的进程,因此参数不能直接通过内存来传递。甚至有时候我们的客户端与服务端都不是使用同一种语言来实现的。由于我们的参数需要经过网络传输,所以参数最终必须转换成二进制的数据,而参数是在内存中的,所以我们需要将内存中的参数序列化成我们需要的二进制的形式。
在这里需要多说一些有关序列化的内容。我们知道序列化(Serialization)是将程序中的数据结构或对象的状态信息转换为可以存储或者可以通过网络传输的形式的过程,而反序列化(Deserialization)则是序列化的反向过程。在序列化之前,对象或数据结构作为一种结构化的数据被保存在内存当中,由于我们需要将它持久化或者通过网络将它传输到其它机器,此时就需要将内存中的对象进行序列化,从而形成可以取用的格式(例如文件,或经由网络传输)。序列化后的数据格式一般需要满足数据结构化的需求,这里比较有代表性的格式就是 XML 和 JSON。
序列化后数据的格式(也可以称为数据交换格式)大致可以分为三类:自解析型、半解析型和无解析型。自解析型的数据包含完整的结构,包括字段的名称、类型和值,调整不同属性的顺序对序列化和反序列化没有影响,比较有代表性的有 XML、JSON、Java Serialization 以及百度的 mcpack/compack 等。半解析型的数据丢弃了部分信息,比如字段的名称,但引入了 index(通常是 id + type 的方式)来对应具体的属性,比较有代表性的有 Google protobuf、Apache Thrift 等。而无解析型则丢弃了很多有效信息,性能和压缩比最好,但是向后兼容需要做一定的工作,传说中百度的 infpack 就属于此列。
| 数据传输格式 | 类型 | 平台相关性 | 优点 | 缺点 |
|---|---|---|---|---|
| XML | 文本 | 无 | 可读性高,序列化后的数据包含完整的结构,调整不同属性的顺序不影响序列化和反序列化 | 序列化后的数据量大,不支持二进制数据类型 |
| JSON | 文本 | 无 | 可读性高,调整不同属性的顺序不影响序列化和反序列化 | 丢弃了类型信息,比如 “price”: 10,对 price 类型的解析有二义性(是 int 还是 double),不支持二进制数据类型 |
| Java Serialization | 二进制 | Java 平台 | 使用简单 | 可读性较差,序列化后的数据量较大,序列化和反序列化性能较差 |
| Apache Thrift | 二进制 | 无 | 序列化后的数据量较小,序列化和反序列化性能较高 | 可读性较差,向后兼容有一定的限制,采用 id 递增的方式标识并以 optional 修饰来添加 |
| Google protobuf | 二进制 | 无 | 序列化后的数据量较小,序列化和反序列化性能较高 | 可读性较差,向后兼容有一定的限制 |
我们接着说,假设客户端上的应用发起了远程过程调用,方法的参数在序列化之后连同请求一起通过底层的网络协议传输到服务器,服务器在接收到请求后,需要对参数进行反序列化的操作,将参数恢复为内存中的表达方式,然后通过寻址找到对应的方法,从而进行本地调用并得到返回值。返回值同样需要经过序列化返回给客户端上的应用,客户端在接收到响应后,同样需要进行反序列化恢复为内存中的表达方式。
RPC 可以粗略的划分为平台相关和平台无关两大类。平台相关的代表有 Java RMI、.NET Remoting 等。平台无关的有早期的 CORBA、XML-RPC、XML-RPC 的后继者 SOAP、Web Service、JSON-RPC 等,以及很多现代 RPC 框架比如 Google gRPC、Apache Thrift、Apache Avro、Hprose 等。