我们可以把锁理解成门票,只有当线程拿到了门票才能进入临界区。我们可以用一个状态变量 state 表示锁,当 state 为 true 时就表示已经获取到了锁,为 false 时就表示锁已经被其他线程占用。那么当锁被占用时,应该怎么处理?基本上有两种思路,其中一种就是循环检测直到锁可用,也就是自旋锁;另一种就是让出 CPU 时间片,等待唤醒通知。这里主要讨论自旋的算法,为深入学习 AQS 做铺垫。
TAS Lock 自旋锁中最简单的一种实现就是 TAS Lock(Test And Set Lock)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class TASLock { private AtomicBoolean state = new AtomicBoolean (false ); public void lock () { while (this .state.getAndSet(true )) { } } public void unlock () { this .state.set(false ); } }
其中 getAndSet 方法是通过 CAS 的方式自旋设置新值,当新值设置成功后才会返回,返回的值是之前的旧值。因此这里的 lock 方法只有在之前的值为 false 时才会返回,不然会一直自旋等待。也就是说当一个线程调用了 lock 方法后,其他线程再调用 lock 方法就会在此处自旋,直到该线程调用 unlock 方法后,其他线程才有可能退出自旋拿到锁。这种实现方式是在 CAS 操作上自旋,由于 AtomicBoolean 中维护的真实值是用 volatile 修饰的,为了可见性,该变量的修改和获取都需要通过总线与主存交互,CAS 操作一直在修改它的值,这会引发缓存一致性的流量风暴,从而占用总线资源。
TTAS Lock 一种针对 TAS Lock 的改进就是 TTAS Lock(Test Test And Set Lock)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class TTASLock { private AtomicBoolean state = new AtomicBoolean (false ); public void lock () { while (true ) { while (this .state.get()) { } if (!this .state.getAndSet(true )) { return ; } } } public void unlock () { this .state.set(false ); } }
这种方式最大的改进就是将自旋放在了获取 state 上,这样不会引发缓存一致性的流量风暴,但是每次获取 state 值的时候还是需要到主存中去读取。
Anderson’s Lock TAS 和 TTAS 都是基于一个状态变量来标识锁,所有的线程都需要轮询此变量的状态,这才会导致频繁占用总线流量。如果每个线程都有一个自己的状态,那么就可以大幅度的减少总线占用。Anderson’s lock 就是一个使用类似思想实现的锁,它基于数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class ALock { private boolean flags[]; private int size; private AtomicInteger tail; private ThreadLocal<Integer> slot = new ThreadLocal <>(); public ALock (int capacity) { this .size = capacity; this .flags = new boolean [this .size]; this .tail = new AtomicInteger (0 ); this .flags[0 ] = true ; } public void lock () { int index = this .tail.getAndIncrement() % this .size; this .slot.set(index); while (!this .flags[index]) { } } public void unlock () { int index = this .slot.get(); this .flags[index] = false ; this .flags[(index + 1 ) % this .size] = true ; } }
lock 方法会先计算出当前线程状态的位置并将它放到线程本地变量中,然后自旋判断状态,只有当前线程的状态为已经获取到锁(true)时才会退出。unlock 方法会通过线程本地变量获取当前线程状态的位置,然后修改状态为空闲(false),目的是为了其他的线程可以再次使用该位置。接着需要“唤醒”下一个等待的线程,即改变下一个线程的状态为已经获取到了锁。
可以看到,这种方式使用了一个线程共享的数组来存储每个线程的状态(是否获取到了锁),每个线程在自己的工作内存中都有一份该数组的拷贝。线程在获取锁时,只会在自己副本上的特定位置自旋。与 TTAS 相比,能够减少总线的占用,同时这种方式也形成了一个类似 FIFO 的队列,可以保证线程获取锁的公平性。当然缺点也很明显,就是数组长度固定,且空间效率不高,它为每个锁都分配了大小为 size 的数组,如果需要同步 N 个不同的对象就需要分配 N * size 的内存空间,即使线程一次仅访问一个锁。在无缓存的 NUMA 架构中,该算法的性能不佳,因为 lock 可能会在远程变量上自旋。
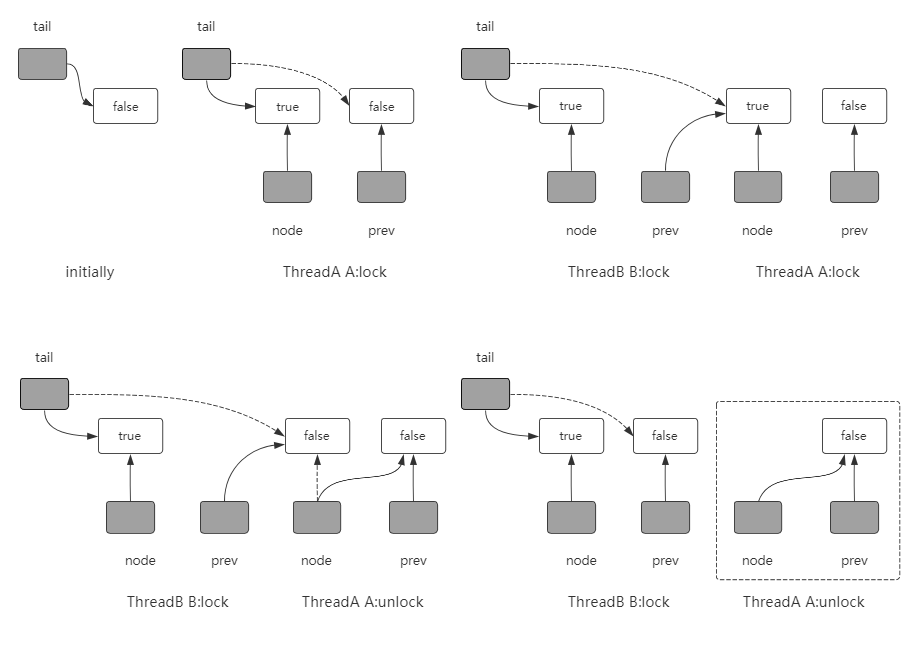
CLH Lock CLH(Craig, Landin, and Hagersten)Lock 可以看作是 Anderson’s Lock 的改进和优化,从结构上看,它是一个虚拟的单向链表(之所以说是虚拟的,或者说是隐式的,是指节点本身并不持有下一个节点)。线程在获取锁时会在它的前驱节点上自旋,当前驱节点的锁释放,该线程就获取到了锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class CLHLock { private final ThreadLocal<Node> prev; private final ThreadLocal<Node> node; private AtomicReference<Node> tail = new AtomicReference <>(new Node ()); public CLHLock () { this .node = ThreadLocal.withInitial(Node::new ); this .prev = ThreadLocal.withInitial(() -> null ); } public void lock () { Node node = this .node.get(); node.locked = true ; Node prev = this .tail.getAndSet(node); this .prev.set(prev); while (prev.locked) { } } public void unlock () { Node node = this .node.get(); node.locked = false ; this .node.set(this .prev.get()); } class Node { private volatile boolean locked; } }
与 Anderson’s Lock 相比,它最大的优点就是空间效率高,但是同样的,它还是具有与 Anderson’s Lock 相同的缺点,那就是在 NUMA 架构中性能不佳。
参考
Section 3 Practice: Spin Locks and Contention