InnoDB 行记录格式
InnoDB 中最小的存储单位为页,默认每页的大小为 16 KB。页中的数据是按行进行存放的,每页中存放的行记录最少为 2 行,最多为 16 KB / 2 - 200 行,也就是 7992 行。
MySQL 目前有四种行记录格式:Redundant、Compact、Dynamic 和 Compressed。其中 Redundant 是以前使用的旧格式,为了兼容性还一直保留。自 MySQL 5.1 开始,默认的行记录格式为 Compact,而从 MySQL 5.7 开始,默认的行记录格式为 Dynamic。使用 SHOW TABLE STATUS LIKE 'table_name' 可以查看指定表的行格式。
1 | mysql> SHOW TABLE STATUS LIKE 'test'\G; |
Compact 行格式
Compact 行记录格式是在 MySQL 5.0 引入的,其设计目标是高效的存储数据。简单来说就是:一个页中存放的行数据越多,其性能就越高。
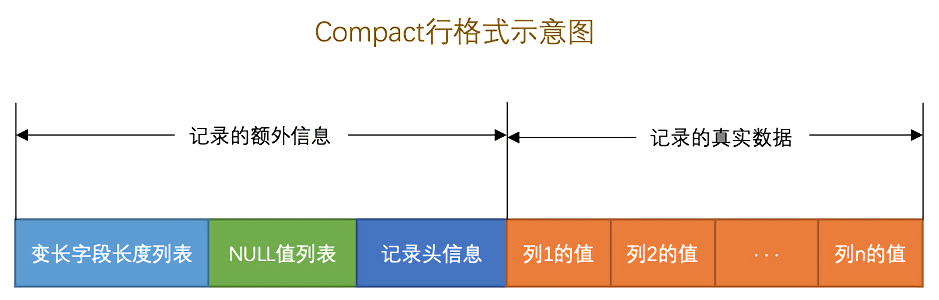
变长字段长度列表
MySQL 支持一些变长的数据类型,比如 VARCHAR(M)、各种 TEXT、各种 BLOB 等类型,使用这些数据类型的列可以称为变长字段。由于变长字段存储多少字节的数据是不固定的,因此我们需要在存储真实数据的时候顺便将这些数据占用的字节数也存储起来。在 Compact 行格式中,会把所有的变长字段的真实数据(非 NULL)占用的字节长度都存放在记录的开头,从而形成一个长度列表,各个变长字段的长度按照列的顺序逆序存放。至于变长字段长度列表中每个列长度使用多少字节来表示是有一套规则的。
首先需要说明 W、M 和 L 的含义:其中 W 为某个字符集中表示一个字符最多需要使用的字节数,这个值可以通过 SHOW CHARSET 命令查看,对应 Maxlen 列的值。比如 utf8 字符集中 W 就是 3,ascii 字符集中的 W 就是 1。对于变长类型 VARCHAR(M) 来说,M 代表该类型能够最多存储的字符个数,再结合使用的字符集,可以得出该类型最多占用的字节数就是 M*W。而 L 代表的是该类型实际存储的字符串占用的字节数。因此有如下规则:
1 | 如果 M*W <= 255,那么使用 1 个字节来表示长度 |
变长字段的长度最大不会使用超过 2 个字节来表示,原因是在 MySQL 中,对于一条记录占用的最大存储空间是有限制的,除了 BLOB、TEXT 类型之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节。假如创建的表只有一列,那么这也就意味着该列最多占用 65535 个字节,使用二进制位来表示最多需要 16 位,也就是 2 个字节即可。
还有一个特别需要注意的点就是:如果使用定长字符集,比如 ASCII 字符集,那么 CHAR(M) 这种的类型占用的字节数就是固定的;如果使用变长字符集,比如使用 UTF8(表示一个字符需要 1 到 3 个字节),那么 CHAR(M) 这种类型所占用的字节数也是不确定的,此时该列的长度也会被存储到变长字段长度列表中。
NULL 标志位
变长字段之后的第二个部分是 NULL 标志位,该部分将每个允许为 NULL 的列都对应一个二进制位,二进制位同样按照列的顺序逆序存放,二进制位为 1 表示列的值为 NULL;为 0 则表示列的值不为 NULL。该部分一般占用 1 个字节,如果允许为 NULL 的字段超过了 8 个,那么就需要 2 个字节。
记录头
记录头信息固定占用 5 个字节,每位的含义如下表:
| 名称 | 大小 | 描述 |
|---|---|---|
| 1 | 预留,未使用 | |
| 1 | 预留,未使用 | |
| delete_mask | 1 | 记录是否被删除 |
| min_rec_mask | 1 | B+树的每层非叶子节点中的最小记录都会添加该标记 |
| n_owned | 4 | 记录拥有的记录数 |
| heap_no | 13 | 记录在索引堆的排序信息 |
| record_type | 3 | 记录的类型,0 表示普通记录,1 表示 B+树非叶子节点,2 表示最小记录 Infimum,3 表示最大记录 Supremum |
| next_record | 16 | 下一条记录的相对位置 |
列值部分
最后的部分就是实际存储的每列的数据。需要注意的是,NULL 值只占用 NULL 标志位,不占用该部分的任何空间。同时每行记录除了用户定义的列外,还有三个隐藏的列,分别是 row_id、transaction_id 和 roll_pointer,对应的真实名称分别为 DB_ROW_ID、DB_TRX_ID 和 DB_ROLL_PTR。其中 row_id 不是一定存在的,只有用户没有定义主键,同时也没有定义一个不能为空的 Unique 键时,InnoDB 才会为表默认添加一个 row_id 隐藏列作为主键。
| 隐藏列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6 个字节 | 行 ID,唯一标识一条记录 |
| transaction_id | 是 | 6 个字节 | 事务 ID |
| roll_pointer | 是 | 7 个字节 | 回滚指针 |
例子
这里创建一张表来具体验证 Compact 行格式:
1 | create table test ( |
在这个表中,有三个变长字段,我们可以通过 hexdump -C -v test.ibd > test.txt 命令将表空间文件重定向至 test.txt 文件后直接打开,找到第一行记录开始的位置:0000c078,发现接下来有三个字节的值分别为:03、02、01,与我们的预期相符。
1 | 0000c070: 73 75 70 72 65 6D 75 6D 03 02 01 00 00 00 10 00 supremum........ |
接下来我们查看整条记录的值,发现都符合预期:
1 | # 变长字段长度列表 |
同样,查看最后一行记录的值,发现也都符合预期:
1 | # 变长字段长度列表 |
行溢出数据
我们已经知道了行记录占用的空间大小最多为 65535 字节,也可以认为是列占用的空间大小不能超过 65535 字节。但是由于一页的大小默认为 16 KB,也就是 16384 字节,并且还有一个限制条件是每页需要至少存储 2 行记录(否则就失去了 B+Tree 的意义,变成链表了),因此很有可能会出现一页中连一条记录都存不下的情况。对于一个页中只能存储一条记录甚至连一条记录都存不下的情况,InnoDB 会将占用存储空间非常大的列拆开,在当前列中只存储该列的前 768 个字节的数据和一个指向溢出页(Uncompressed BLOB Page 类型)的地址。
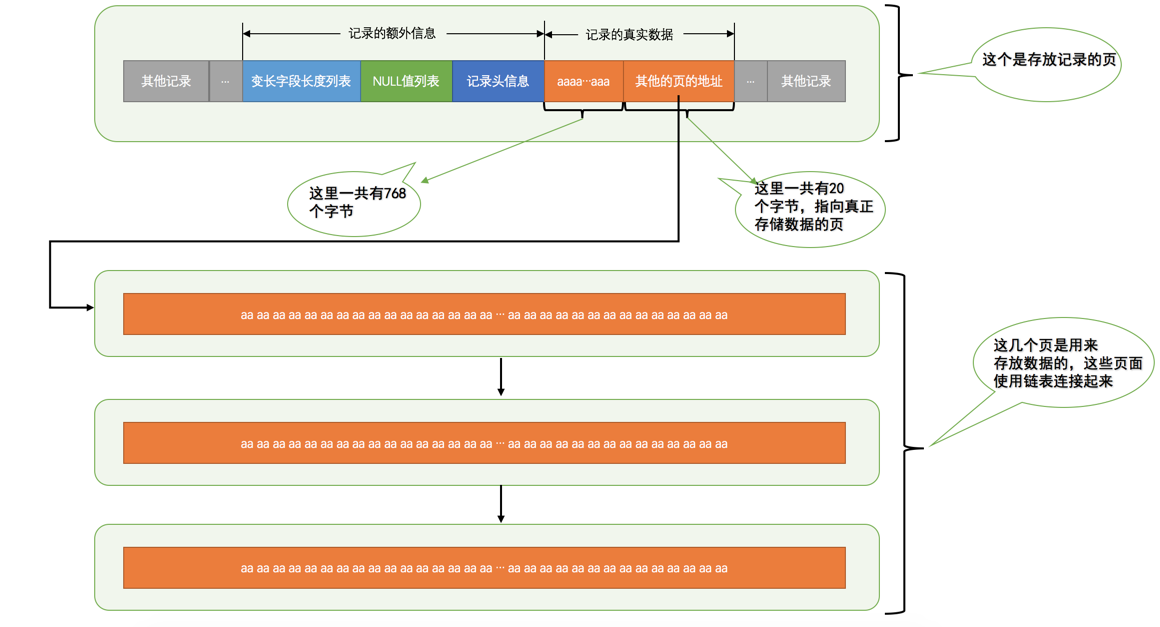
如果可以在一个页中至少放入两行记录,那么 VARCHAR 等类型(TEXT、BLOB 等类型也有可能出现行溢出)的列数据就不会放到 BLOB 页中,MySQL 技术内幕一书中提到长度阈值为 8098,也就是说当一个表只有一列,且该列的定义为:VARCHAR(8098) 时,正好可以存放两条记录而不会出现行溢出的情况。其实我们可以不用关注这个临界点是多少,我们只需要知道如果一条记录占用的字节数过多时,就有可能出现行溢出。
Dynamic 和 Compressed 行格式
InnoDB 1.0.x 版本开始引入了新的文件格式(可以理解为新的页格式),以前支持的 Compact 和 Redundant 格式称为 Antelope 文件格式,新的文件格式称为 Barracuda,该文件格式下拥有两种新的行记录格式:Dynamic 和 Compressed。
新的两种行记录格式对于存放在 BLOB 中的数据采用了完全行溢出的方式,即连 768 个字节的数据也被移到了溢出页中,数据页(B-Tree Node)中只存放了 20 个字节的溢出页地址。同时 Compressed 行记录格式会对行数据使用 zlib 算法进行压缩,因此在存储 BLOB、TEXT、VARCHAR 这类大长度类型的数据时比较有优势。
参考
《MySQL 技术内幕:InnoDB 存储引擎》