简单理解分布式系统与时钟
分布式系统中,不同节点的物理时钟很难实现完全一致,即使我们给所有节点一个相同的起始时间,在经过一段时间后,节点之间的物理时钟也有很大可能会出现不一致。导致这种问题的根本原因是由于计算机的时钟是通过晶体振荡器实现的。晶体振荡器在通电后,内部的石英晶体会产生谐振,这种震荡的频率是稳定和精确的,比如为 10 MHz,处理器可以根据晶振的波形(震荡的次数)来计算时间。但是由于晶振的频率会受到温度变化的影响,因此机器工作时的温度变化会导致时钟过快或过慢,从而影响时钟的准确性。
选用高精度的晶振固然可以减缓这个问题,但是高精度的晶振同样成本也高。而采用 NTP 时钟同步虽然可以矫正时间,但是由于网络延迟、同步频率等因素的影响,各个节点的物理时钟还是很难保持精确一致。
当应用程序需要协作时,它们通过交换信息来协调它们的动作,而密切的协作通常取决于对程序动作发生时间的共识,达成共识的前提是我们需要知道一个事件发生的时间,也就是时间序列或者时间戳。在单体应用中,时间序列的获取是很容易的,即使计算机的时间与真实时间有出入,但是只要在一个计算机内,不同的进程获取的时间序列之间的顺序性是可以保证的(不考虑时钟回拨);而在分布式应用中,不同机器的时钟很可能不同,并且我们也很难通过普通的手段实现多节点之间的时钟同步,这样也就无法确定系统中事件发生的顺序。
然而实际在很多应用中,机器不一定要求跟实际时间相一致,只需要所有的机器具有相同的时间就够了。或者更进一步来说,分布式应用中节点的交互只要在事件发生的顺序上达成共识即可,不需要对事件发生的时间达成共识。
Lamport 逻辑时钟
1978 年 Lamport 在《Time, Clocks and the Ordering of Events in a Distributed System》中提出了逻辑时钟的概念,通过判断事件的因果关系来决定事件的先后顺序。
偏序(Partial Ordering)
在论文中,作者将事件序列分为了两种:偏序事件序列和全序事件序列。所谓偏序指的是只为系统中的部分事件定义先后顺序,这里的部分事件指的是具有因果关系的事件,这种因果关系可以理解为在分布式系统中节点是否存在交互,同时根据这种因果关系可以将事件分为三类,一类发生在节点(或者进程)内部的事件,一类是发送消息的事件,一类是接收消息的事件。同时作者还定义了一种叫做 happened before 的偏序关系,这种关系具有以下几个规则:
- 如果事件 a 和事件 b 在同一个进程中发生,并且 a 在 b 之前发生,那么记作
a -> b。 - 如果事件 a 是发送消息,事件 b 是接收该消息,那么 a 在 b 之前发生(消息的传递需要时间),记作
a -> b。 - 如果
a -> b,并且b -> c,那么a -> c。另外如果两个事件 a 和 b 既不满足a -> b,也不满足b -> a,那么可以说两个事件是并发(concurrent)的。
实际上,在分布式系统中,只有两个发生关联(进行过数据交换)的事件,我们才会去关心两者发生的先后顺序,而对于不存在交互的并发事件,我们可以不用考虑它们的时序问题。
逻辑时钟
Lamport 逻辑时钟是一个单调增长的软件计数器,它的值与任何物理时钟无关。这个逻辑时钟的规则如下:
- 每个节点在本地维护一个 logic clock 记作 LCi,每个事件对应一个 Lamport Timestamp,初始值为 0。
- 如果事件在节点内发生,则本地时间戳加 1,即 LCi = LCi + 1。
- 如果事件是发送事件,那么本地时间戳加 1,并在消息中带上该时间戳。
- 如果事件是接收事件,那么在收到消息后 LCj = max(LCj, 消息中的时间戳) + 1。
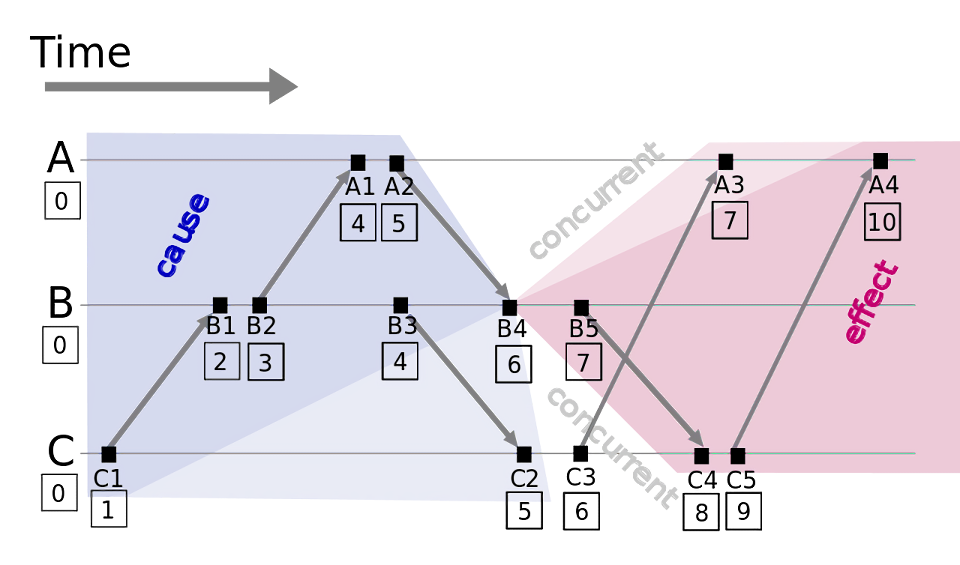
通过这种算法,可以保证如果 a -> b,那么 C(a) < C(b),但是无法通过比较两个逻辑时钟的大小来得到 a 和 b 的先后顺序,比如下面这种:
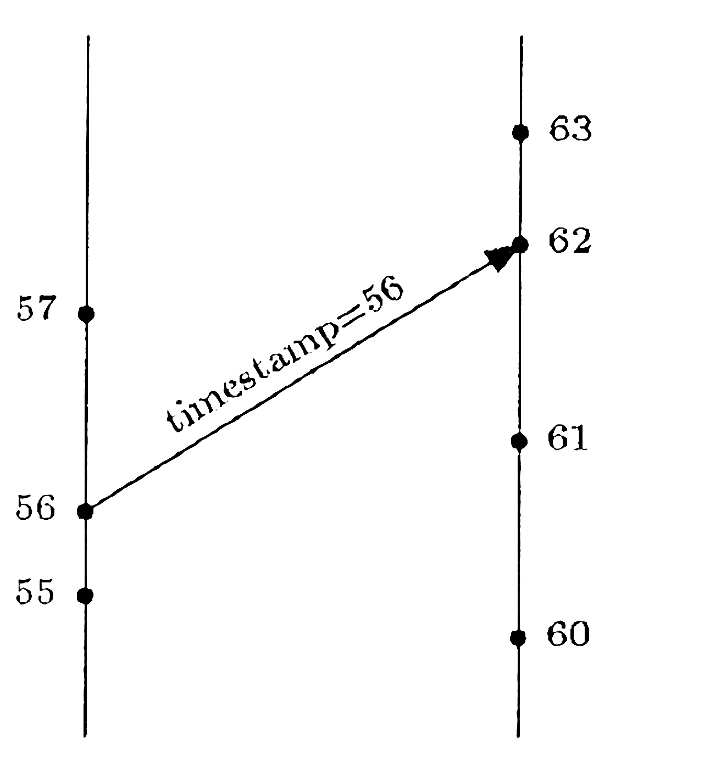
逻辑时间为 56 的事件向另一个事件发送消息,从而得到另一个事件的逻辑时间为 62,尽管它的逻辑时间小于 61,但是它却是在逻辑时间为 61 的事件之后发生的。
全序(Total ordering)
通过定义,我们知道如果 a -> b,那么 C(a) < C(b),但是如果 C(a) = C(b) 的时候,a 与 b 应该是什么先后顺序呢?由于它们肯定不是因果关系,所以它们之间的先后顺序其实并不会影响结果,我们只需要给出一种确定的方式来定义它们之间的先后顺序,就可以得到一个全序关系。一种可行的方式是给进程编号,并根据进程编号的大小来排序。在上图中我们假设进程 A、B、C 的编号分别为 1、2、3,那么虽然 C(B4) = C(C3),但是由于 B 的编号小于 C,所以它们的先后顺序是 B4 -> C3。但是从上图还会发现,从时间轴来看 B5 应该早于 A3 发生,但是我们给出的全序关系中 A3 却是早于 B5 的,这是因为 Lamport 逻辑时钟只能保证因果关系的正确性,无法保证时序的正确性。同时全序关系也不是唯一的,与选定的方式有关。
向量时钟(Vector Clock)
Vector Clock 是在 Lamport 逻辑时钟的基础上演进的另一种逻辑时钟算法,它使用 Vector 结构不光记录本节点的 Lamport 时间戳,同时还会记录其他节点的 Lamport 时间戳。具体来说,每个节点都维护一个向量 VC,同时在这个向量中:VCi[i] 是到目前为止节点 i 上发生的事件的个数,而 VCi[k] 则为节点 i 知道节点 k 中发生的事件的个数。向量时钟通过以下算法进行更新:
- 节点 i 本地发生的事件会将 VCi 加 1。
- 节点 i 给节点 j 发送消息时,会将整个 VCi 存在消息中。
- 节点 j 收到消息后,VCj[k] = max(VCj[k], VCi[k]),同时 VCj[j] 加 1。
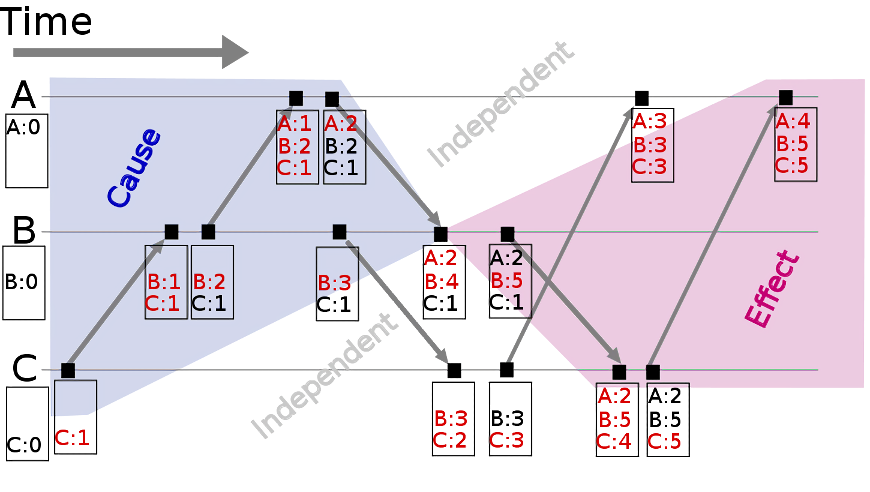
为什么使用向量时钟
对于一个数据库系统(或者存储系统)来说,需要一种机制来界定事务或者操作的先后顺序,如果是单机数据库,可以在事务提交时通过获取时间戳作为事务 ID,时间戳小的事务即为更早提交的事务。而到了分布式系统中,如果是单点写,则同样可以沿用这种方式;但是如果是一个支持多点写的系统,那么机器之间必然存在时钟误差,如果多个节点对同一条记录进行修改,那么就有可能出现在 wall time 上先提交的事务的 ID 反而更小,此时就可以通过向量时钟来处理这种冲突。
2007 年亚马逊的一篇论文:Dynamo: Amazon’s Highly Available Key-value Store 提到了亚马逊的 Dynamo 使用了 Vector Clock(Version Clock),但似乎在很早的时候就已经摒弃了这种做法。原因可能与向量时钟的缺陷有关,首先每次请求都要先向对方获取一次版本,这在性能上不好接受。向量时钟只能帮助发现冲突,但无法解决冲突。Cassandra 之前就发表过一篇文章:Why Cassandra doesn’t need vector clocks 说明了他们为何没有使用向量时钟。
参考
《Time, Clocks and the Ordering of Events in a Distributed System》