Git 内部原理
这篇博文主要用于记录博主在学习 Git 官方教程时的整个过程和一些心得体会,具体学习的章节是《Git 内部原理》。
底层命令与上层命令
我们平常使用的 git 命令一般都是对用户友好的上层(porcelain)命令,然而,由于 Git 最初只是一套面向版本控制系统的工具集,所以它还包含了一部分用于完成底层工作的子命令,这部分命令一般称为底层(plumbing)命令。
目录结构
当在一个新目录或已有目录执行 git init 时,Git 会创建一个 .git 目录。 这个目录包含了几乎所有 Git 存储和操作的东西。如果想备份或复制一个版本库,只需把这个目录拷贝至另一处即可。新初始化的 .git 目录的典型结构如下:
1 | config |
description 文件仅供 GitWeb 程序使用,我们无需关心。config 文件包含项目特有的配置选项。info 目录包含一个全局性的排除(global exclude)文件,用于放置那些不希望被记录在 .gitignore 文件中的忽略模式(ignored patterns)。hooks 目录包含客户端或服务端的钩子脚本(hook scripts)。
剩下的四个条目很重要:HEAD 文件、(尚未创建的)index 文件,和 objects 目录、refs 目录。它们都是 Git 的核心组成部分。objects 目录存储所有的数据内容;refs 目录存储指向数据(分支、远程仓库和标签等)的提交对象的指针;HEAD 文件指向目前被检出的分支;index 文件保存暂存区信息。
Git 对象
Git 的核心部分是一个简单的键值对数据库。我们可以向 Git 仓库中插入任意类型的内容(文本或文件),它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容。底层命令 git hash-object 可以实现该效果:将任意数据保存到 objects 目录,并返回指向该数据对象的唯一的键。
1 | $ git init test |
可以看到,Git 对 objects 目录进行了初始化,并创建了 pack 和 info 子目录,但均为空。接着,我们用 git hash-object 创建一个新的数据对象并将它手动存入 Git 数据库中:
1 | $ echo 'test content' | git hash-object -w --stdin |
其中,-w 选项指示该命令不光要返回键,还要将该对象写入数据库中。--stdin 选项则指示该命令从标准输入读取内容,如果不指定此选项,则须在命令尾部给出需要存储的文件的路径。比如:
1 | $ echo 'test content' > test.txt |
该命令输出的是一个长度为 40 个字符的哈希值,该校验和通过将待存储的数据外加一个头部信息(header)一起做 SHA-1 校验运算得到。现在我们可以查看 Git 是如何存储数据的:
1 | $ find .git/objects -type f |
再次查看 objects 目录,可以在其中找到一个与新内容对应的文件。这就是 Git 存储内容的方式:一个文件对应一条内容,以该内容加上特定头部信息一起做 SHA-1 校验和来为文件命名。校验和的前两个字符用于命名子目录,余下的 38 个字符则用作文件名。
一旦将内容存储在了对象数据库中,那么就可以通过 cat-file 命令从 Git 仓库取回数据(如果直接使用 cat 命令查看写入的内容,会发现全是乱码,这是因为写入的东西是经过压缩的)。指定 -p 选项可指示该命令自动判断内容的类型,并为我们显示大致的内容:
1 | $ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 |
接下来我们尝试对一个文件进行简单的版本控制。首先,创建一个新文件并将其内容存入数据库:
1 | $ echo 'version 1' > test.txt |
接着,向文件里写入新内容,并再次将其存入数据库:
1 | $ echo 'version 2' > test.txt |
对象数据库记录下了该文件的两个不同版本,当然之前我们存入的第一条内容也还在:
1 | $ find .git/objects -type f |
接下来我们可以删除该文件,同时只需要通过 cat-file 传入不同的键,就可以取回该文件的第一个版本和第二个版本:
1 | $ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 |
然而,记住文件的每一个版本所对应的 SHA-1 值并不现实;另一个问题是,在这个(简单的版本控制)系统中,文件名并没有被保存。上述类型的对象我们称之为数据对象(blob object)。利用 git cat-file -t 命令,可以让 Git 告诉我们其内部存储的任何对象类型,只要给定该对象的 SHA-1 值:
1 | $ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a |
树对象
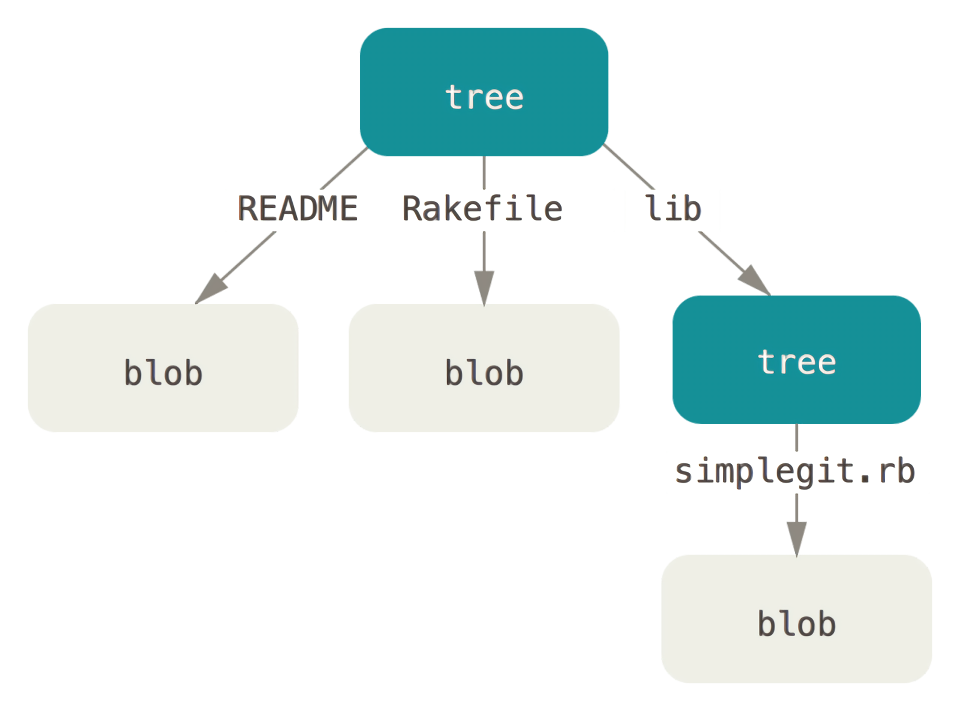
Git 以一种类似于 UNIX 文件系统的方式存储内容,所有内容均以树对象和数据对象的形式存储。其中树对象对应 UNIX 中的目录,数据对象则大致对应 inodes 或文件内容。一个树对象包含一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或子树对象的 SHA-1 指针,以及相应的模式、类型和文件名信息。例如,某个项目当前对应的最新树对象可能是这样的:
1 | $ git cat-file -p master^{tree} |
master^{tree}语法表示 master 分支上最新的提交所指向的树对象。
通常,Git 根据某一时刻暂存区(index 文件)所表示的状态创建并记录一个对应的树对象,如此重复便可以依次记录(某个时间段内)一系列的树对象。因此,为了创建一个树对象,首先需要通过暂存一些文件来创建一个暂存区。可以通过底层命令 git update-index 为一个单独文件(之前 test.txt 文件的首个版本)创建一个暂存区。
1 | $ git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test.txt |
使用该命令,可以将 test.txt 的首个版本人为地加入到一个新的暂存区,--add 选项表示此前该文件并不在暂存区中(我们甚至都没有创建过一个暂存区)。--cacheinfo 选项表示该文件位于 Git 数据库中,而不是当前目录下。同时还需要指定文件模式、SHA-1(Git 数据库对象的键)和文件名。
Git 中的文件模式参考了 UNIX 的文件模式,但远没有那么灵活。数据对象只有三种文件模式:普通文件 100644、可执行文件 100755、符号链接 120000。还有一些其他的文件模式用于目录项和子模块。
接下来可以通过 git write-tree 命令将暂存区的内容写入到一个树对象。这里不用指定 -w 选项,如果某个树对象此前并不存在的话,调用此命令会根据当前暂存区的状态自动创建一个新的树对象。
1 | $ git write-tree |
接下来我们创建一个新的数对象,它包含 test.txt 文件的第二个版本,以及一个新的文件:
1 | $ echo 'new file' > new.txt |
暂存区现在包含了 test.txt 文件的新版本和一个新文件:new.txt。记录下这个目录树(将当前暂存区的状态记录为一个树对象)。
1 | $ git write-tree |
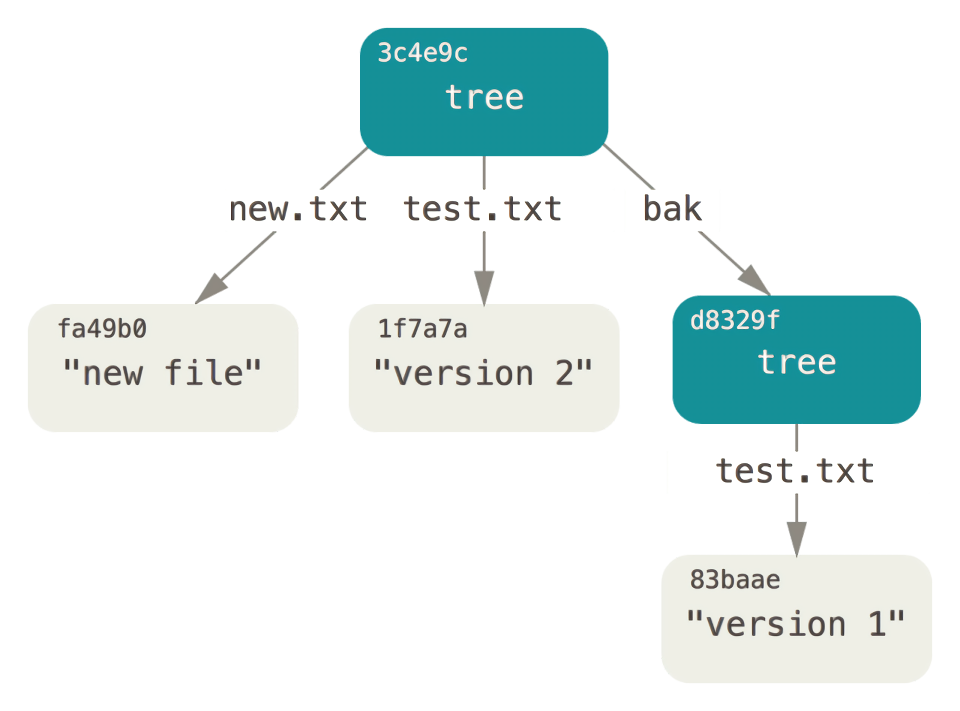
我们发现新的树对象包含两条文件记录,同时 test.txt 的 SHA-1 值就是之前该文件的第二个版本。我们还可以将第一个树对象加入到第二个树对象中,使其成为新树对象的一个子目录。使用 git read-tree 命令可以将一个树对象读入暂存区。
1 | $ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579 |
提交对象
现在我们已经有了三个树对象,它们代表我们想要跟踪的不同项目的快照。然而我们要想重用这些快照,还是需要提供它们的 SHA-1 值,并且我们也不知道是谁保存了这些快照,在什么时候保存的,以及为什么保存这些快照。而以上这些信息,都可以通过提交对象(commit object)来保存。
可以通过 commit-tree 命令创建一个提交对象,为此需要指定一个树对象的 SHA-1 值,以及该提交的父提交对象(如果有的话)。我们先从之前创建的第一个树对象开始:
1 | $ echo 'first commit' | git commit-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 |
由于创建时间和作者数据不同,现在及之后的散列值都有可能不同。
提交对象的格式很简单:它先指定一个顶层树对象,代表当前项目快照。然后是可能存在的父提交,之后是作者和提交者信息(外加时间戳),接着留空一行,最后是提交注释。
接着,我们将创建另外两个提交对象,它们分别引用各自的上一个提交作为其父提交对象:
1 | $ echo 'second commit' | git commit-tree 0155eb -p 444dd71 |
现在,如果对最后一个提交的 SHA-1 值运行 git log 命令,你会发现已经有一个货真价实的、可由 git log 查看的 Git 提交历史了:
1 | $ git log --stat 1dd880 |
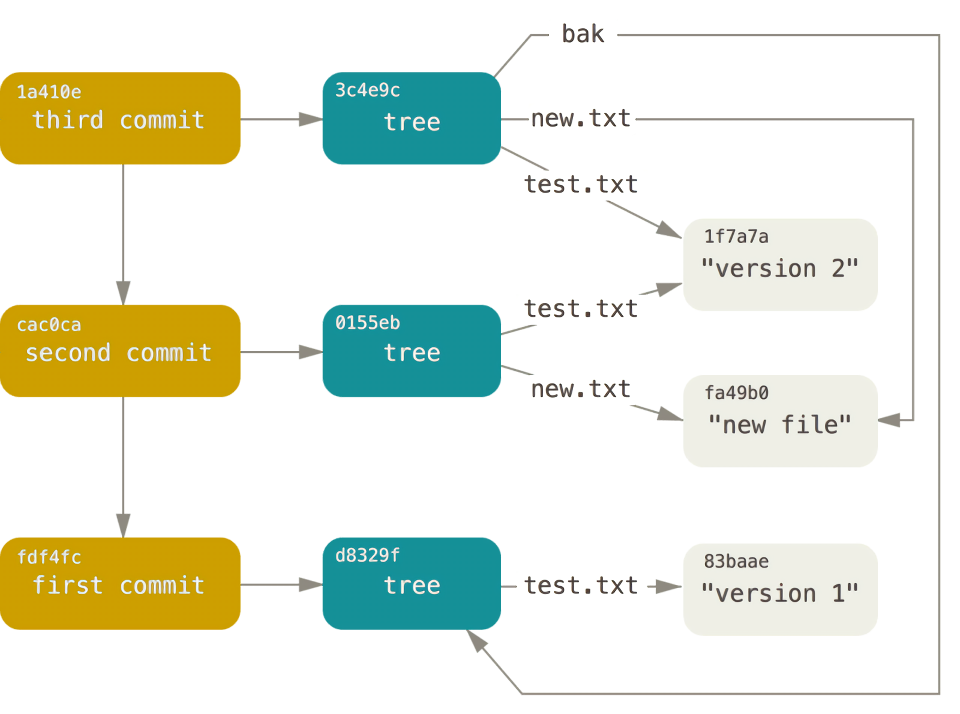
我们没有借助任何上层命令,仅凭几个底层操作便完成了 Git 提交历史的创建。这就是我们在执行 git add 和 git commit 命令时,Git 所做的工作:将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。如果跟踪所有的内部指针,可以得到类似下面的对象关系图:
Git 引用
如果想查看一个提交(比如 1dd880)之前的历史,可以运行 git log 1dd880 命令,但是这样我们需要记住 1dd880 是我们查看历史的起点提交。如果我们能有一个文件来保存这个 SHA-1 值,同时该文件又有一个简单的名字,使用这个名字指针替代原始的 SHA-1 值会使查看日志变得更加简单。
在 Git 中,这个简单的名字被称为引用(references,简写为 refs),可以在 .git/refs 目录下找到它们。在当前的项目中,这个目录下并没有任何文件,但它包含了一个简单的目录结构:
1 | $ find .git/refs |
如果要创建一个新的引用来帮助记录最新提交所在的位置,从原理上讲,只需要执行以下操作:
1 | $ echo 1dd880144c02a460642d6d00c204a86289c23fe7 > .git/refs/heads/master |
接下来就可以使用这个刚创建的新引用来替代 SHA-1 值查看 log 记录了:
1 | $ git log --pretty=oneline master |
不过 Git 并不提倡直接编辑引用文件,如果想更新某个引用,Git 提供了一个更加安全的命令 update-ref 来完成这项工作。
1 | $ git update-ref refs/heads/master 1dd880144c02a460642d6d00c204a86289c23fe7 |
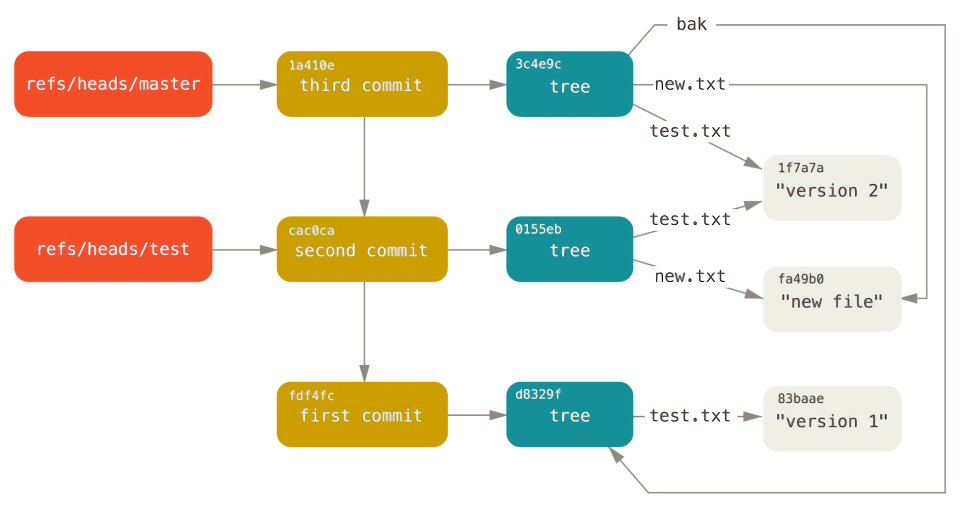
这基本上就是 Git 分支的本质:一个指向某一系列提交之首的指针或引用。当运行类似于 git branch <branch_name> 这样的命令时,Git 实际上执行的是 update-ref 命令,取得当前所在分支最新提交对应的 SHA-1 值。如果想在第二个提交上创建一个新分支,可以这样做:
1 | $ git update-ref refs/heads/test 5dd39238bee9e686bd8436140c5e07776c5bc73b |
HEAD 引用
那么 Git 在执行 git branch <branch_name> 时,又是如何得知当前分支最新提交的 SHA-1 值的呢?答案是 HEAD 文件。HEAD 文件通常是一个符号引用(symbolic reference),它是一个指向其他引用的指针,指向当前所在的分支。在你检出一个标签、提交或远程分支时,HEAD 文件可能会包含一个 git 对象的 SHA-1 值,这是因为此时仓库处于分离 HEAD状态。
直接查看 HEAD 文件内容,通常是:ref: refs/heads/master,如果执行 git checkout test,Git 会更新这个值:
1 | $ cat .git/HEAD |
当我们执行 git commit 时,该命令会创建一个提交对象,并用 HEAD 文件中的那个引用所指向的 SHA-1 值设置其父提交字段。我们可以手动编辑该文件,当然 Git 同样提供了一个更安全的命令 git symbolic-ref 来完成这件事。
1 | # 查看 HEAD 引用的值 |
标签引用
Git 中除了数据对象、树对象和提交对象,实际上还有一种对象:标签对象(tag object),它非常类似于提交对象,包含一个标签创建者信息,一个日期,一段注释,以及一个指针。标签对象与提交对象的主要区别在于,标签对象的指针指向的通常是一个提交对象,而不是一个树对象。它就像一个永不移动的分支引用,永远指向同一个提交对象,只不过是给这个提交对象指定了一个更加友好的名字罢了。
Git 中存在两种类型的标签:附注标签和轻量标签。轻量标签可以直接通过指定一个固定的引用,也就是提交对象来创建。
1 | $ git update-ref refs/tags/v1.0 5dd39238bee9e686bd8436140c5e07776c5bc73b |
而若要创建一个附注标签,Git 会创建一个标签对象,然后记录一个引用来指向该标签对象。也就是说:标签引用中存储的并不是某个提交对象,而是一个指向该标签对象的引用。我们可以通过创建一个附注标签来验证这一过程(使用 -a 选项)。
1 | $ git tag -a v1.1 1dd880144c02a460642d6d00c204a86289c23fe7 -m 'test tag' |
要注意的是,标签对象并非必须指向某个提交对象,我们可以对任意类型的 Git 对象打标签。例如,在 Git 源码中,项目维护者将他们的 GPG 公钥添加为一个数据对象,然后对这个对象打了一个标签。可以克隆一个 Git 版本库,然后通过执行下面的命令在这个版本库中查看上述公钥:
1 | $ git cat-file blob junio-gpg-pub |
远程引用
如果我们添加了一个远程版本库并对其执行过推送操作,Git 会记录下最近一次推送操作时每一个分支所对应的值,并保存在 refs/remotes 目录下。例如,你可以添加一个叫做 origin 的远程版本库,然后把 master 分支推送上去:
1 | $ git remote add origin git@github.com:nekolr/simplegit-progit.git |
此时查看 refs/remotes/origin/master 文件,可以发现 origin 远程版本库的 master 分支所对应的 SHA-1 值,就是最近一次与服务器通信时本地 master 分支所对应的 SHA-1 值。
远程引用和分支(位于 refs/heads 目录下的引用)之间最主要的区别在于:远程引用是只读的。虽然可以 git checkout 某个远程引用,但是 Git 并不会将 HEAD 引用指向该远程引用。因此,你永远不能通过 commit 命令来更新远程引用。Git 将这些远程引用作为记录远程服务器上各分支最后已知位置状态的书签来管理。