主要讨论 Kafka 分区与生产者和消费者之间的分配关系。
分区与生产者
生产者在往主题发送消息时,首先需要确定这条消息最终要发送到哪个分区上,为此 Kafka 提供了多种选择分区的策略。在 Kafka 2.4 以前,默认的策略是:如果指定了分区,则消息投递到指定分区。如果未指定分区,但是指定了 key,那么通过 hash(key) 来计算分区。如果分区和 key 都没有指定,则轮询选择分区。
1
2
3
4
5
6
7
8
9
|
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
|
在 Kafka 2.4 中,默认的分区器中实现了粘性分区(Sticky Partition),这个就不展开了,具体可以看这篇译文。
分区与消费者
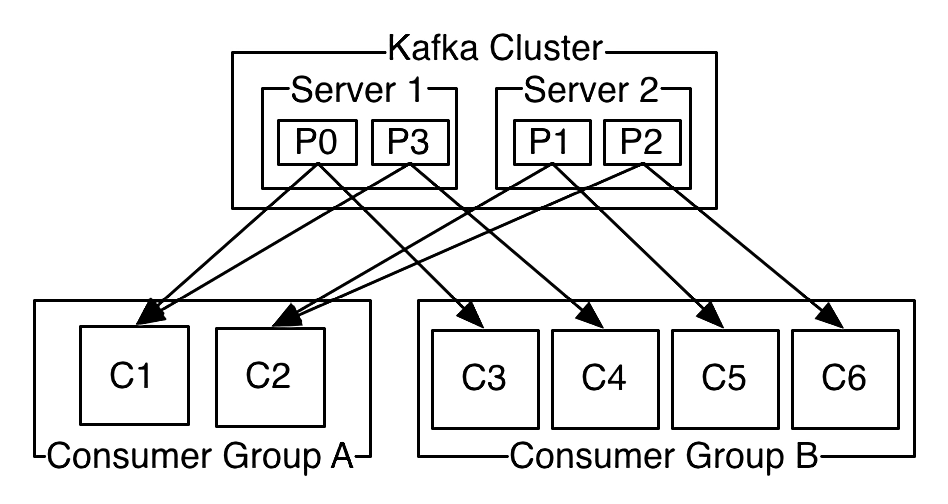
在 Kafka 中,一个主题(topic)下可以有一个或多个分区(partition),消费者以分组的形式订阅主题,分组内可以有一个或多个消费者。同一时刻,一条消息只能被同一组内的某个消费者消费。这就意味着,在一个主题下,如果分区数大于消费者的个数,那么必定有消费者同时消费 2 个或以上的分区;如果分区数等于消费者的个数,那么正好一个消费者对应一个分区;如果分区数小于消费者的个数,那么必定有消费者处于空闲状态。
当消费者组成员变更时,包括成员加入或离开(比如 shutdown 或 crash),消费者组订阅的主题数变更时(主要发生在基于正则表达式订阅主题,当有新匹配的主题创建时)以及消费者组订阅的主题分区数变更时,Kafka 都将进行一次分区分配的过程,这个过程也叫做再平衡(rebalance)。再平衡过程中,如何分配分区则需要根据消费者的分区分配策略来实现,它可以通过 partition.assignment.strategy 属性来配置,Kafka 默认提供了三种策略:range、roundrobin 和 sticky。
range
range 策略基于每个主题,按照序号排列可用分区,以字典顺序排列消费者,将分区数除以消费者数,得到每个消费者的分区数。如果没有平均划分,那么最初的几个消费者将有一个额外的分区。
假设有两个消费者 c0 和 c1,两个主题 t0 和 t1,每个主题有三个分区,即 t0p0,t0p1,t0p2,t1p0,t1p1,t1p2。那么使用 range 分配策略得到的结果就是:
1
2
| c0 [t0p0,t0p1,t1p0,t1p1]
c1 [t0p2,t1p2]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List<String> consumersForTopic = topicEntry.getValue();
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
|
round robin
轮询策略基于所有可用消费者和所有可用分区,与 range 策略最大的不同是它不再局限于某个主题。如果所有的消费者的订阅都是相同的,那么就可以均衡分配。
假设有两个消费者 c0 和 c1,两个主题 t0 和 t1,每个主题有三个分区,即 t0p0,t0p1,t0p2,t1p0,t1p1,t1p2。那么最终的分配结果为:
1
2
| c0 [t0p0,t0p2,t1p1]
c1 [t0p1,t1p0,p1p2]
|
事实上,同组也可以订阅不同的主题。如果组中的每个消费者订阅的主题都不相同,分配的过程仍然使用轮询的方式,若消费者没有订阅主题,那么就要跳过该实例,这有可能会导致分配不平衡。也就是说,消费者组是一个逻辑概念,同组意味着同一时刻分区只能被一个消费者实例消费,换句话说,同组意味着一个分区只能分配给组中的一个消费者。
假设有三个消费者 c0、c1、c2 和三个主题 t0、t1、t2,三个主题分别具有 1、2、3 个分区,因此分区为:t0p0、t1p0、t1p1、t2p0、t2p1、t2p2。如果 c0 订阅 t0,c1 订阅 t0、t1,c2 订阅 t0、t1、t2,那么最终分配的结果为:
1
2
3
| c0 [t0p0]
c1 [t1p0]
c2 [t1p1,t2p0,t2p1,t2p2]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<>());
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet()));
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
assignment.get(assigner.next()).add(partition);
}
return assignment;
}
public List<TopicPartition> allPartitionsSorted(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
SortedSet<String> topics = new TreeSet<>();
for (Subscription subscription : subscriptions.values())
topics.addAll(subscription.topics());
List<TopicPartition> allPartitions = new ArrayList<>();
for (String topic : topics) {
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic != null)
allPartitions.addAll(AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic));
}
return allPartitions;
}
|
sticky
前两种分配策略,如果遇到 rebalance 的情况,分区的调整可能会比较大,而粘性分区策略则可以保证在尽量均衡的前提下减少分配结果的变动。